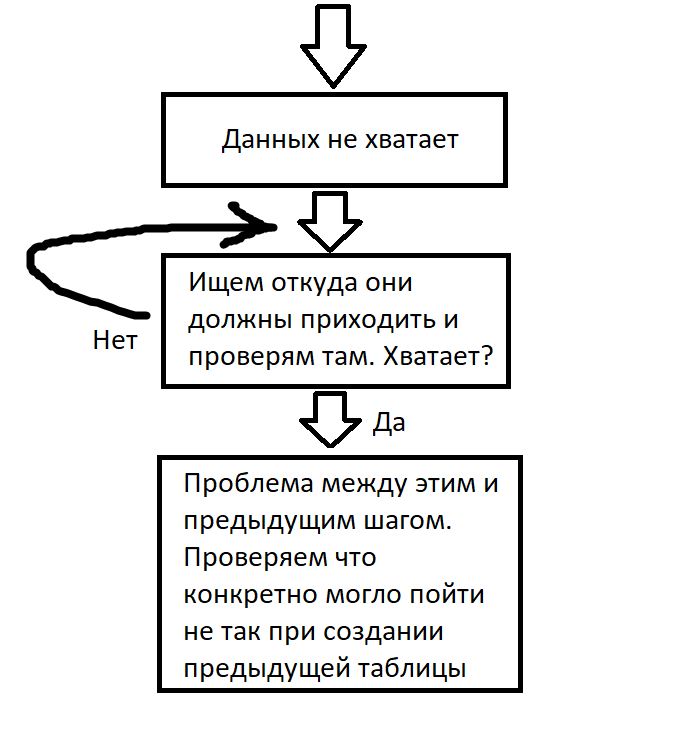
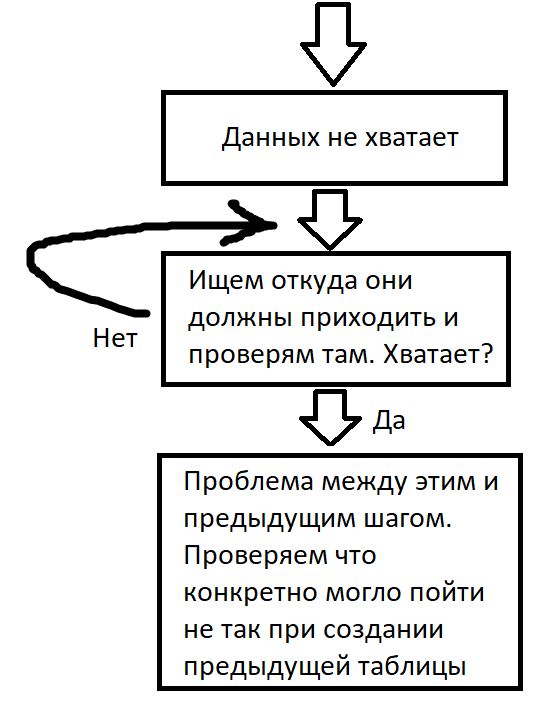
Основной алгоритм проверки выглядит так:
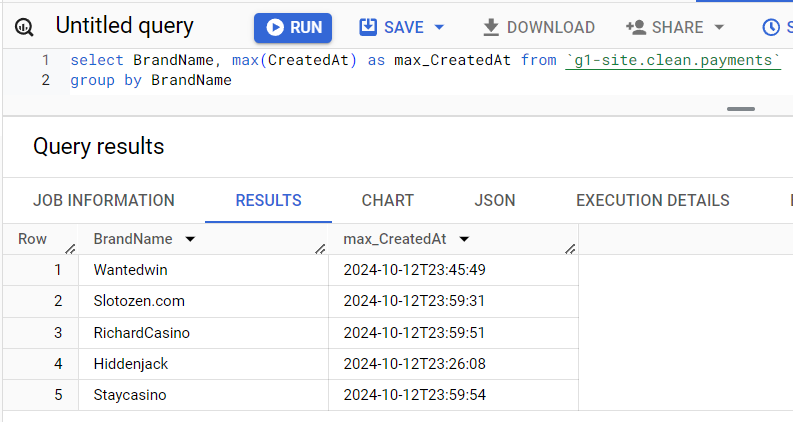
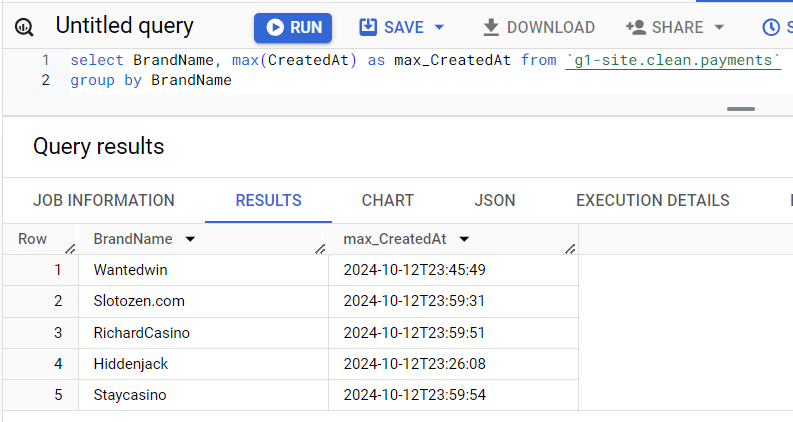
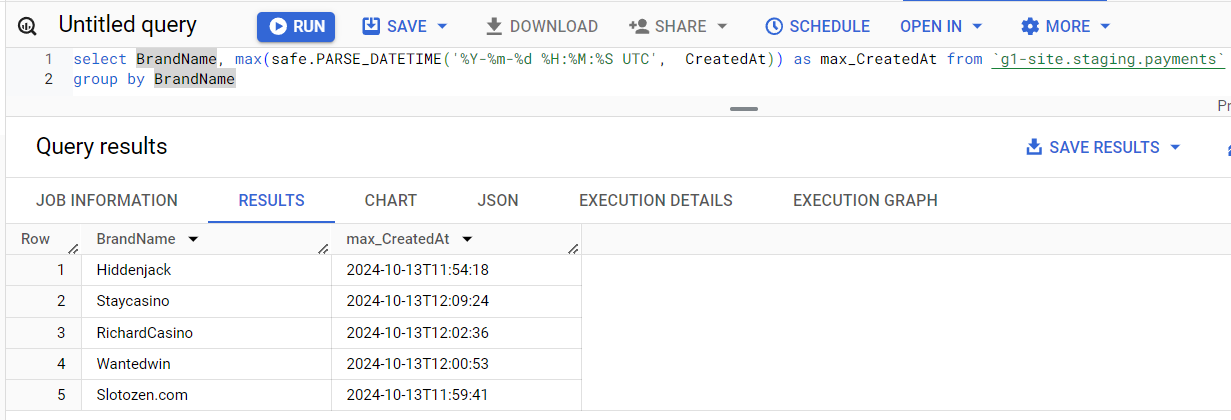
Когда возникает подозрение, что у нас не выгрузились данные за какой-то период, первым делом нужно проверить соответствующую таблицу. Легче всего просто взять крайнее время записи в разбивке по брендам. Данные выгружаются для репортов по-разному, но они точно должны быть за вчера. Например, если сегодня 2024-10-13, то на скриншоте нормальная ситуация на текущий момент - есть данные за 23:00 вчерашнего дня. Но если сегодня 2024-10-14, то данные отстают.
select BrandName, max(CreatedAt) as max_CreatedAt from `g1-site.clean.payments` group by BrandName
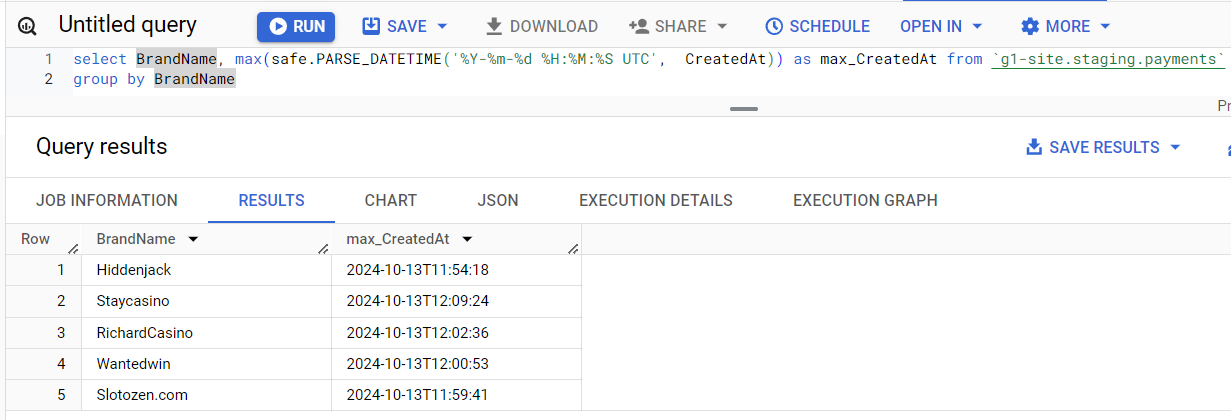
Данные в g1-site.clean таблицы, в основном, приходят из g1-site.staging таблиц. Соответственно проверяем там и обращаем внимание на то, что типы данных одного и того же столбца могут отличаться. Например, в клин таблицах столбец CreatedAt имеет тип данных DATETIME, а в стейджинге - STRING. Тут то же самое, если есть данные как минимум за 23:00 вчерашнего дня - всё норм, если нет - идем дальше.
select BrandName, max(safe.PARSE_DATETIME('%Y-%m-%d %H:%M:%S UTC', CreatedAt)) as max_CreatedAt from `g1-site.staging.payments`
group by BrandName
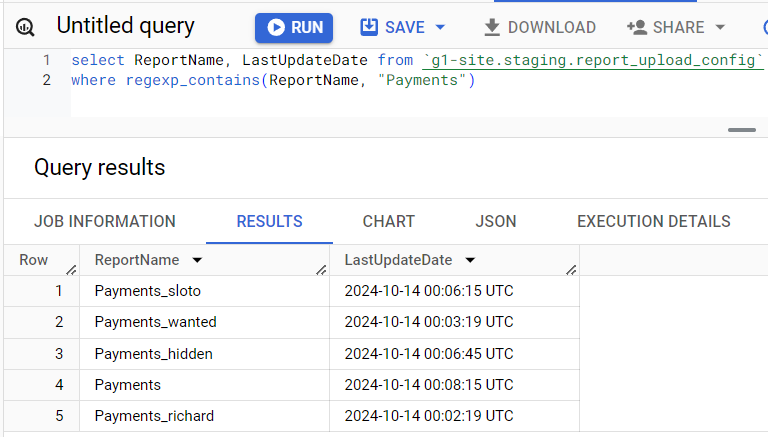
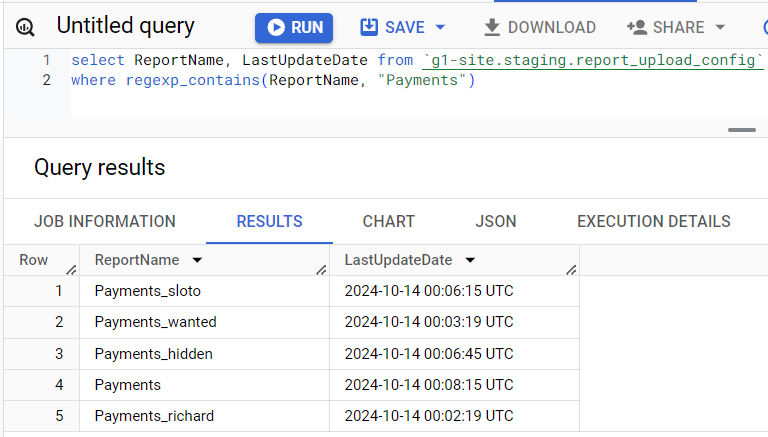
Данные в стейджинг таблицы попадают с сервера, проверяем время последней загрузки. Если тут что-то не так - идем на сервер.
select ReportName, LastUpdateDate from `g1-site.staging.report_upload_config` where regexp_contains(ReportName, "Payments")
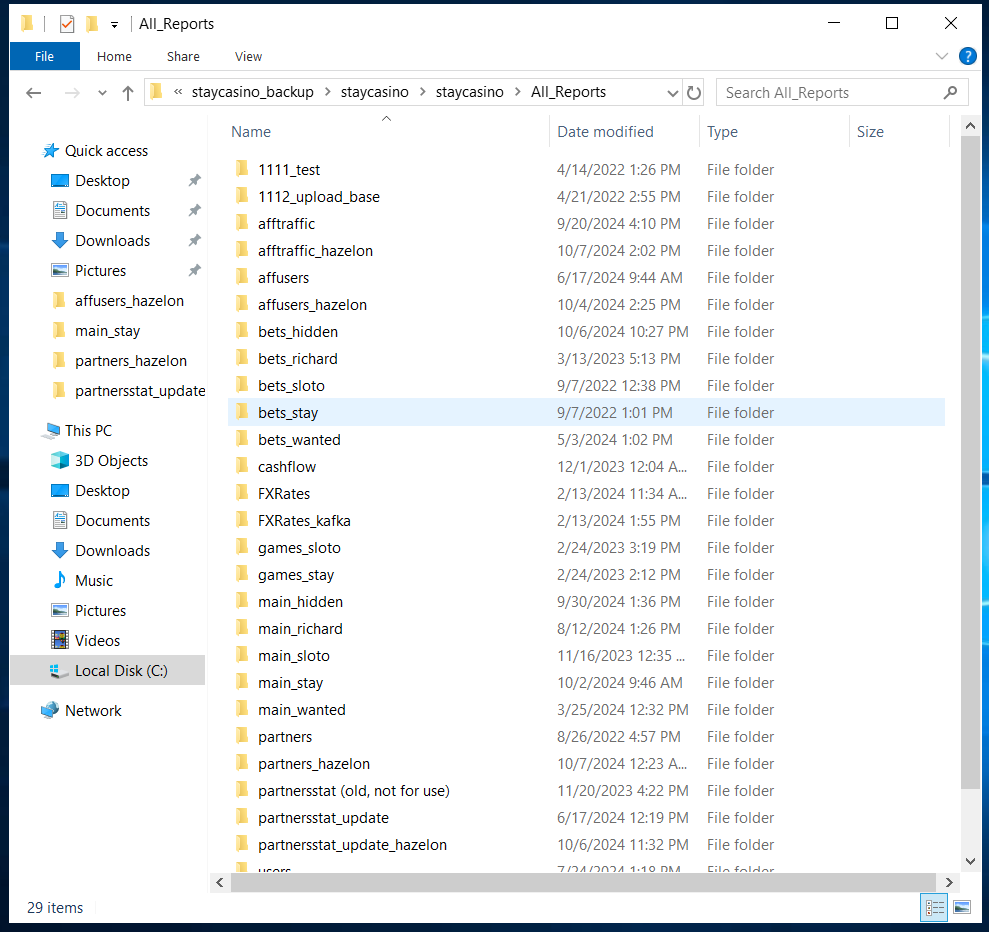
Основная часть репортов выгружается скриптами, расположенными по пути C:\admin\staycasino_backup\staycasino\staycasino\All_Reports. Единственное исключение - доп. инфа по платежам, она выгружается тут C:\admin\staycasino\paym.
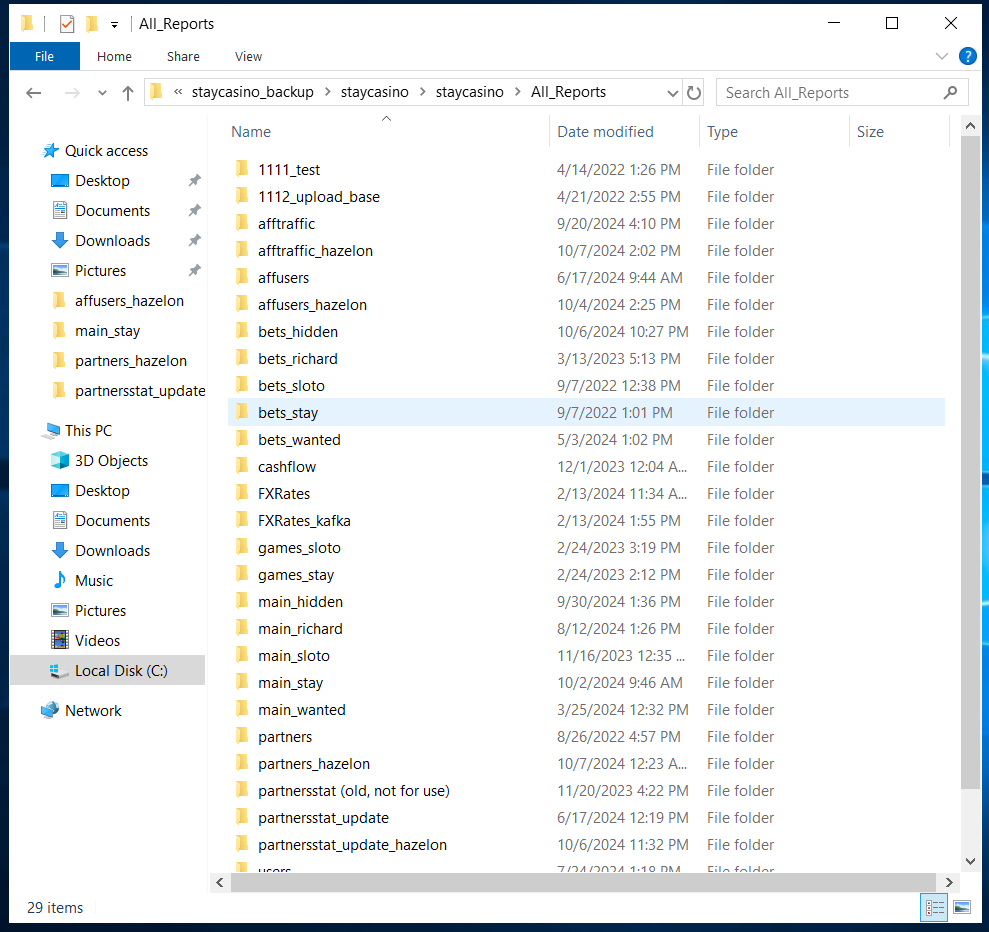
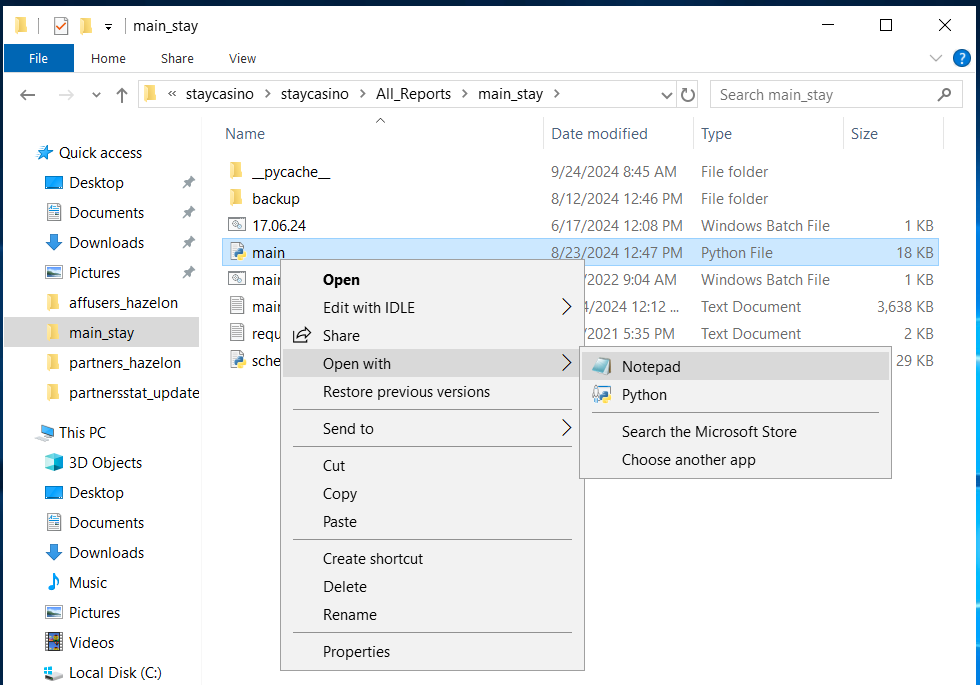
Тут ориентируемся по названию папок. Если всё равно не понятно, в какой конкретно папке происходит та или иная выгрузка, то заходим в папки с непонятными названиями, открываем главный скрипт (в основном он подписан как main.py) через блокнот (или копируем себе на комп и там смотрим).
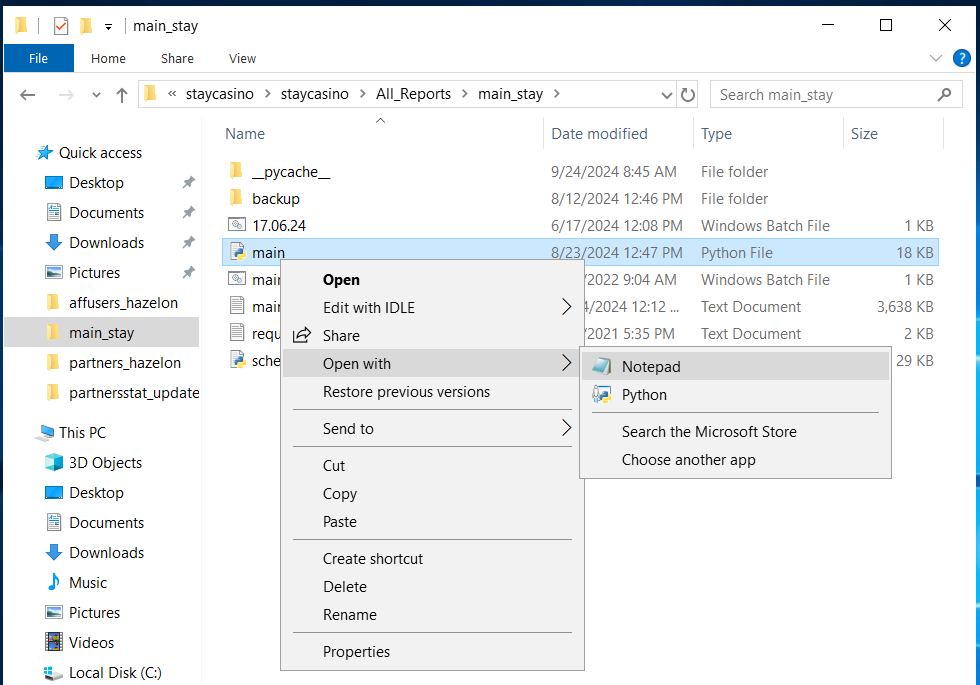
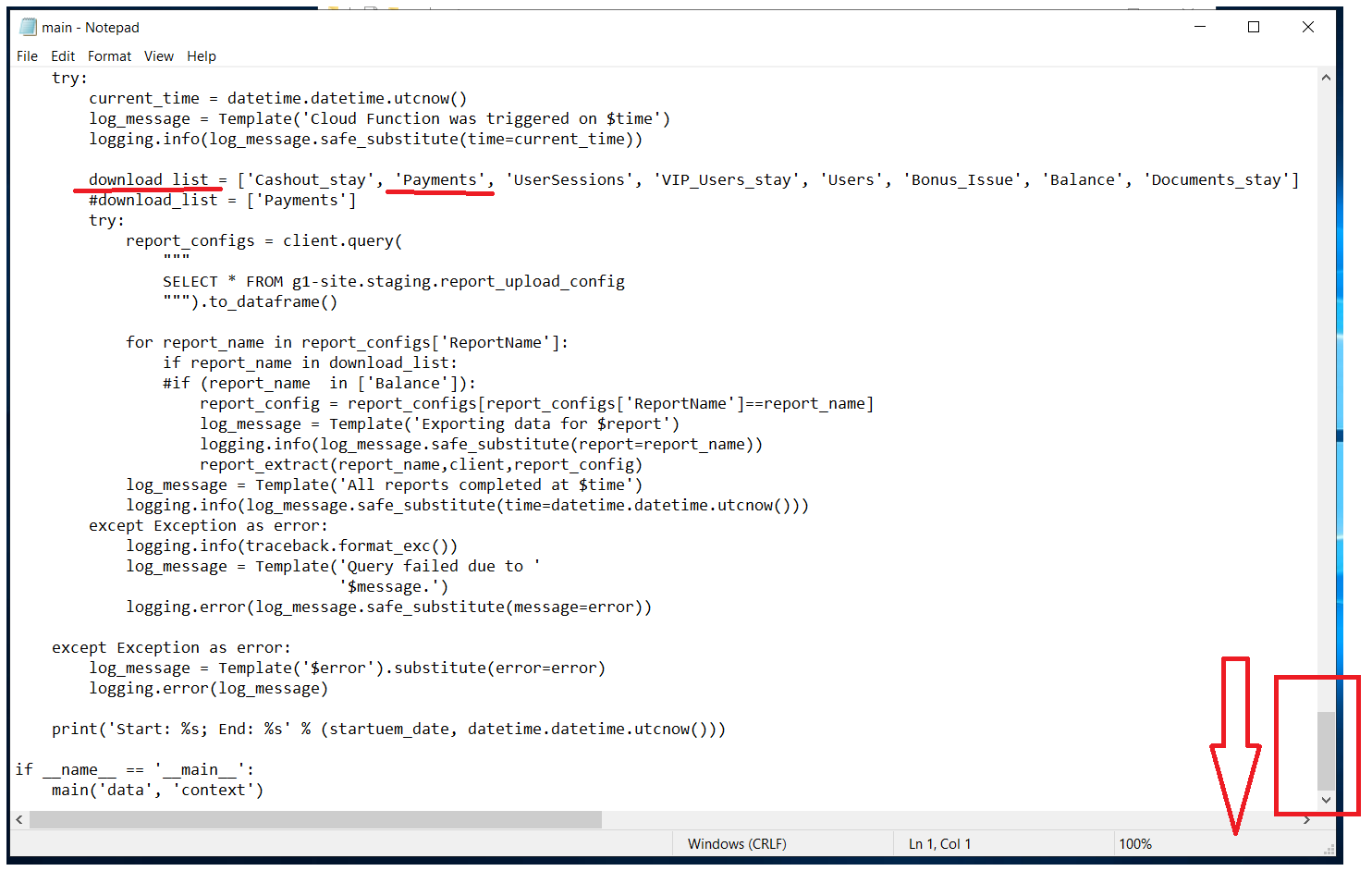
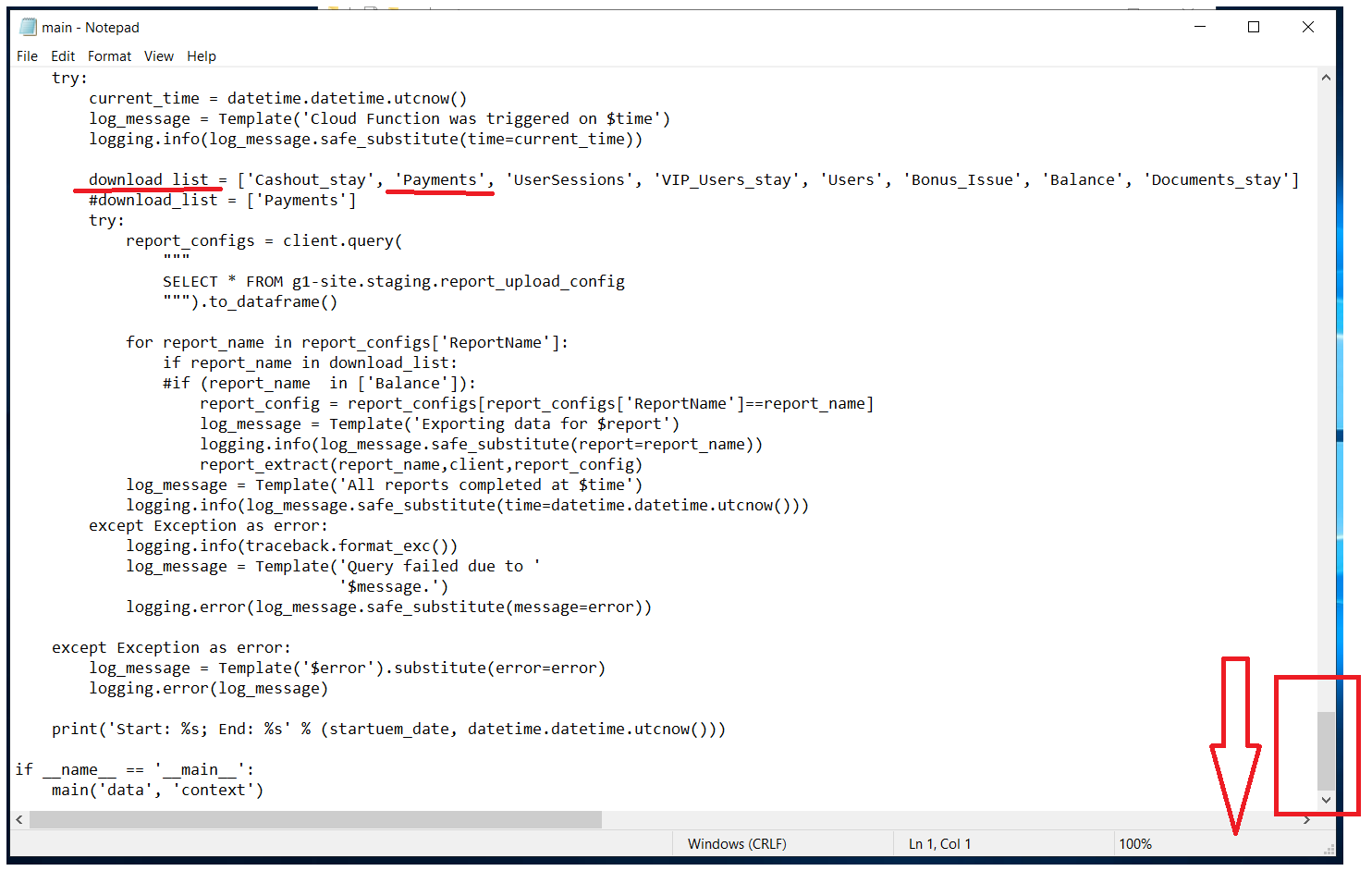
Листаем в самый низ и проверяем download_list. Если там есть искомая таблица, то отлично, если нет - ищем дальше.
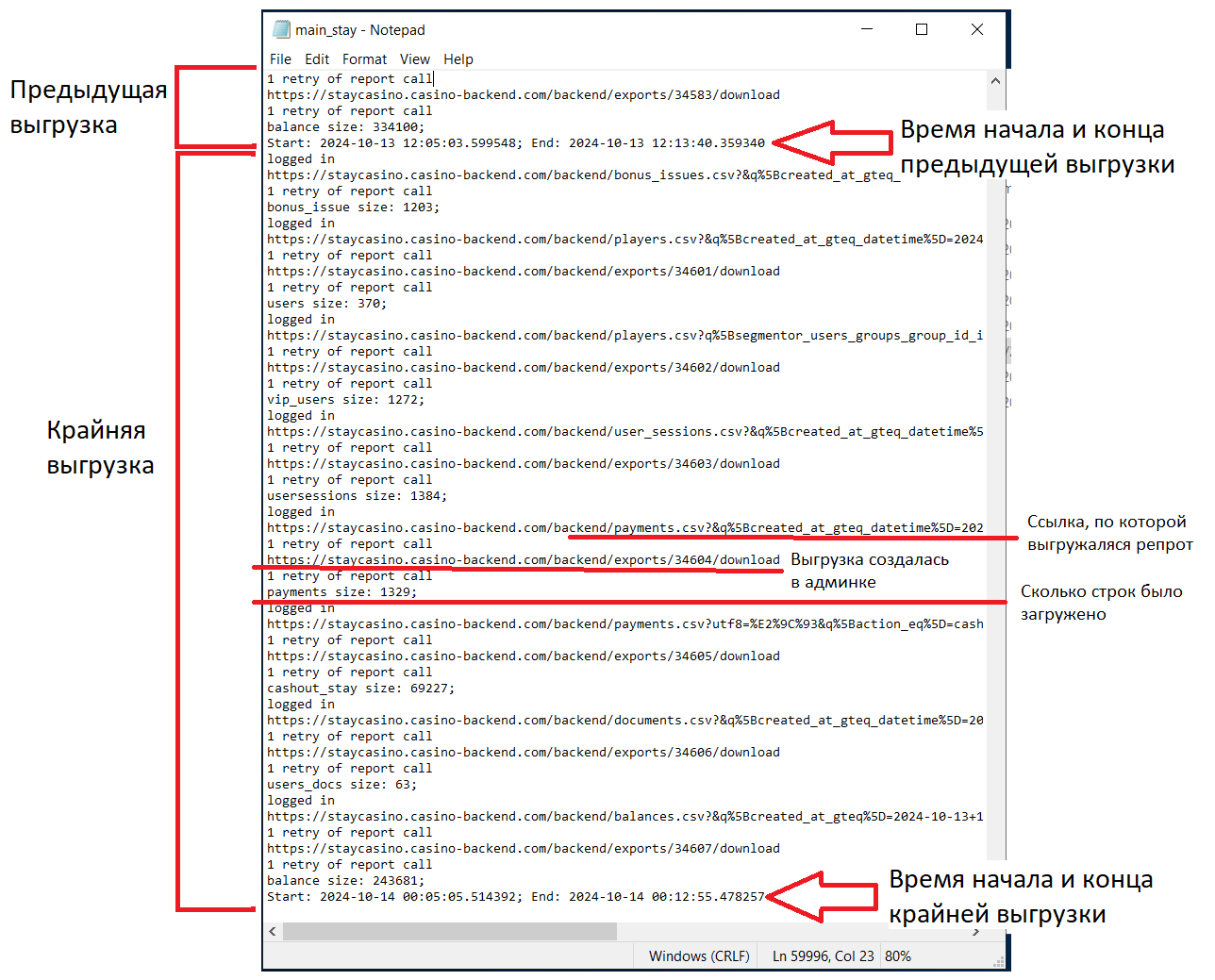
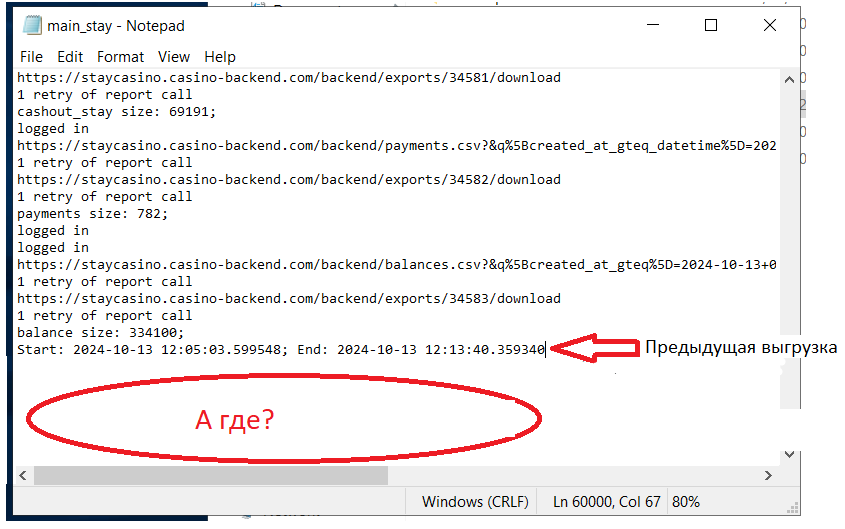
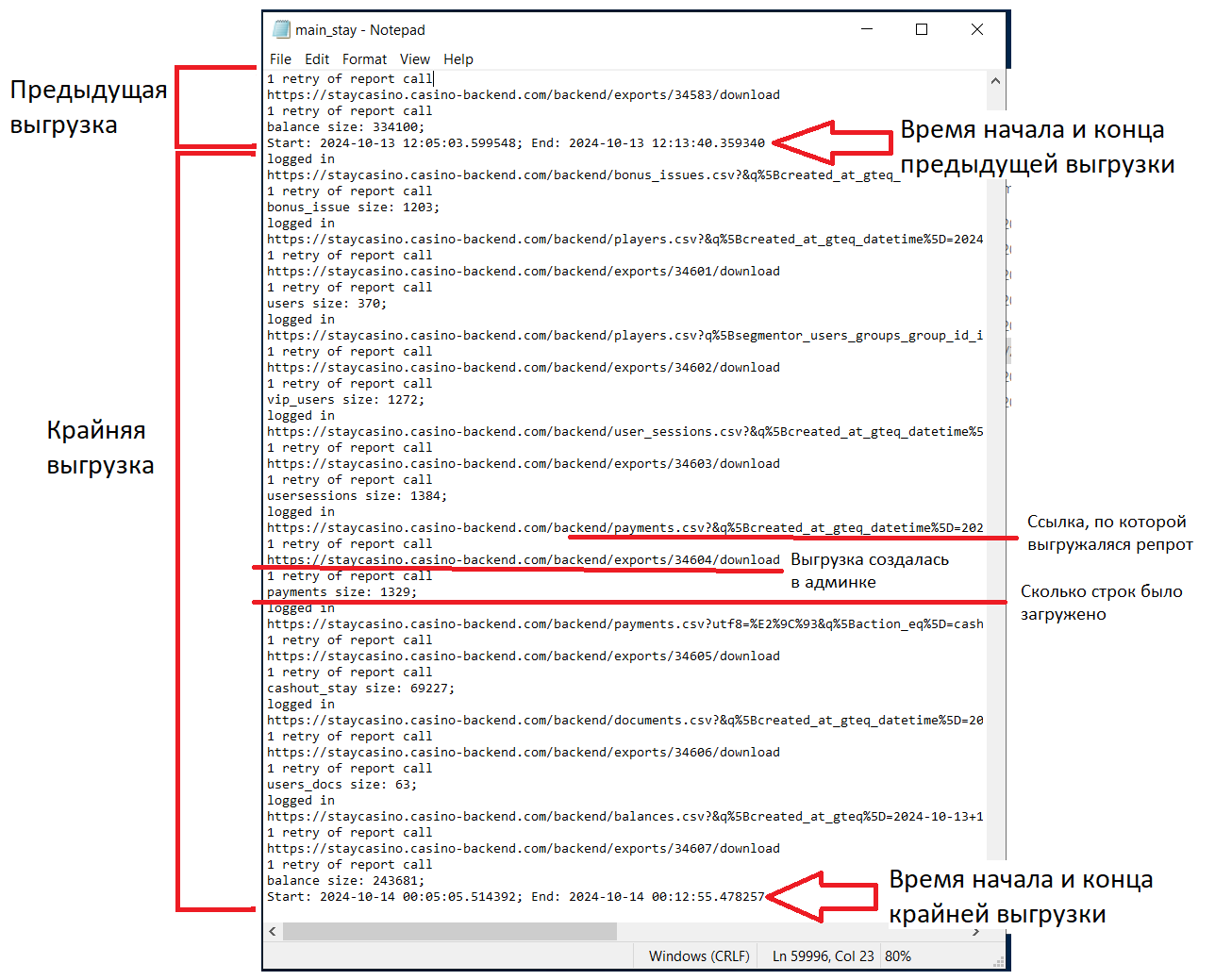
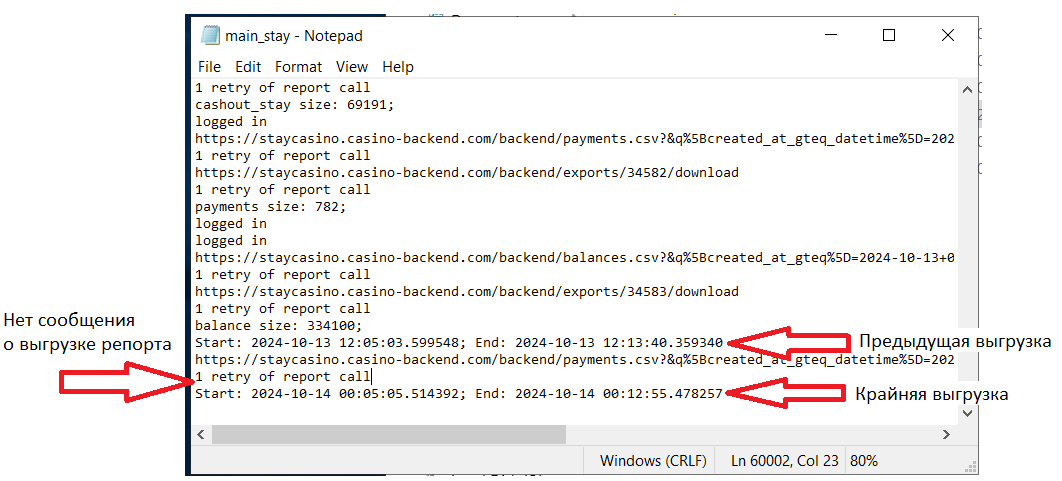
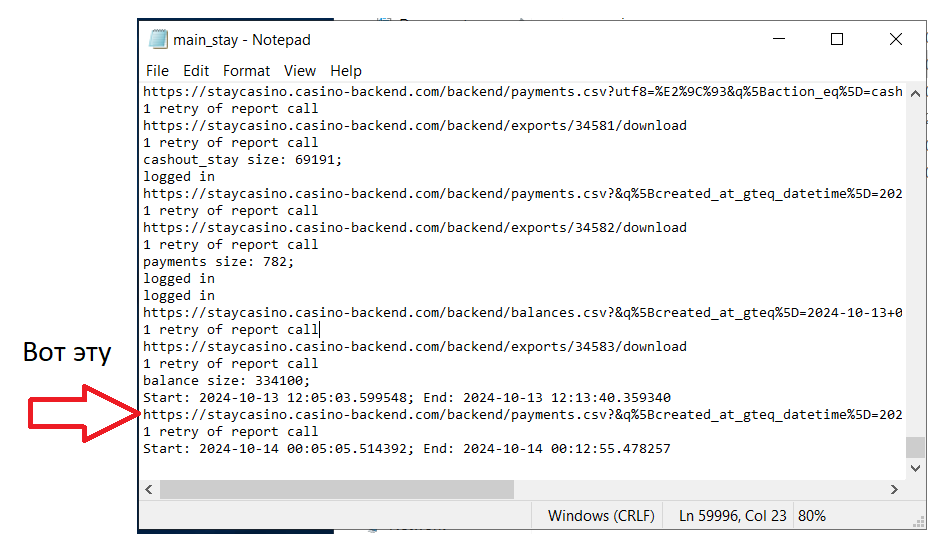
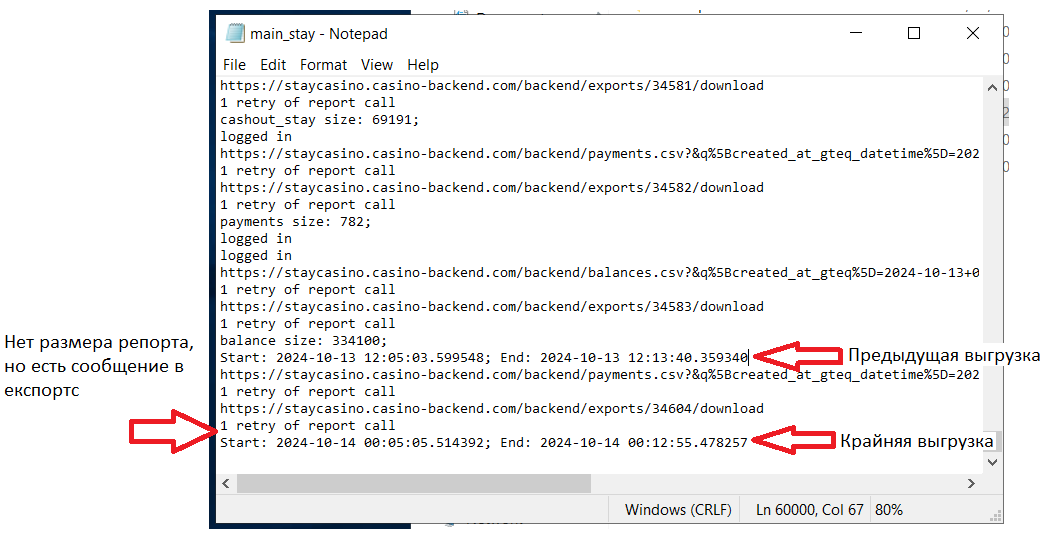
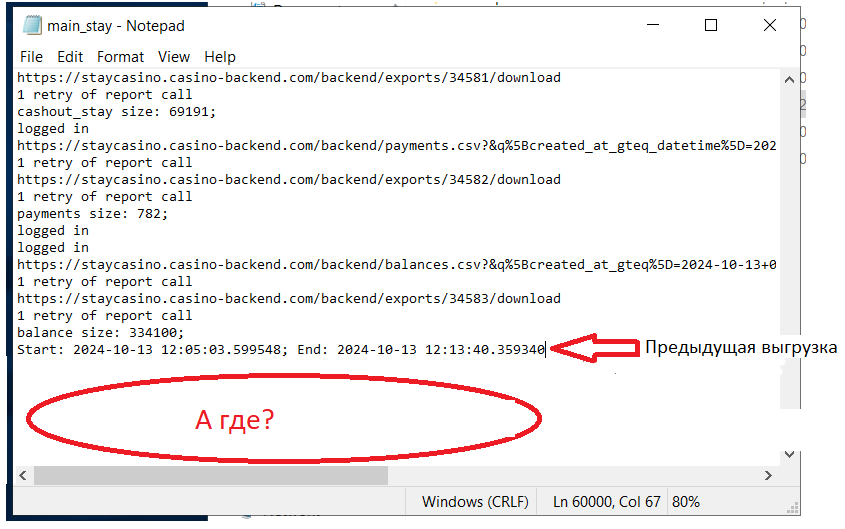
Когда нашли нужную папку - проверяем логи, они должны находиться в файле с разрешением .log. Скрипт за один запуск может выгружать сразу несколько таблиц. Структура логов простая (но может отличаться в зависимости от репорта): Ссылка на загружаемый репорт -> Сообщение о экспорте из админки -> Кол-во выгруженных строк -> Следующий репорт или сообщение о завершении скрипта. По такому логу можно частично понять что именно пошло не так, рассмотрим ситуации.
Первая ситуация - проблемы с логином в админку или репортом
Отличительные черты - нет сообщения по “/backend/exports” и кол-ва выгруженных строк. ВНИМАНИЕ! Некоторые репорты могут выгружаться без “/backend/exports”, тут ситуативно и нужно опираться на предыдущие логи. Листаете вверх, ищите нужную таблицу и сверяете с тем, что есть сейчас.
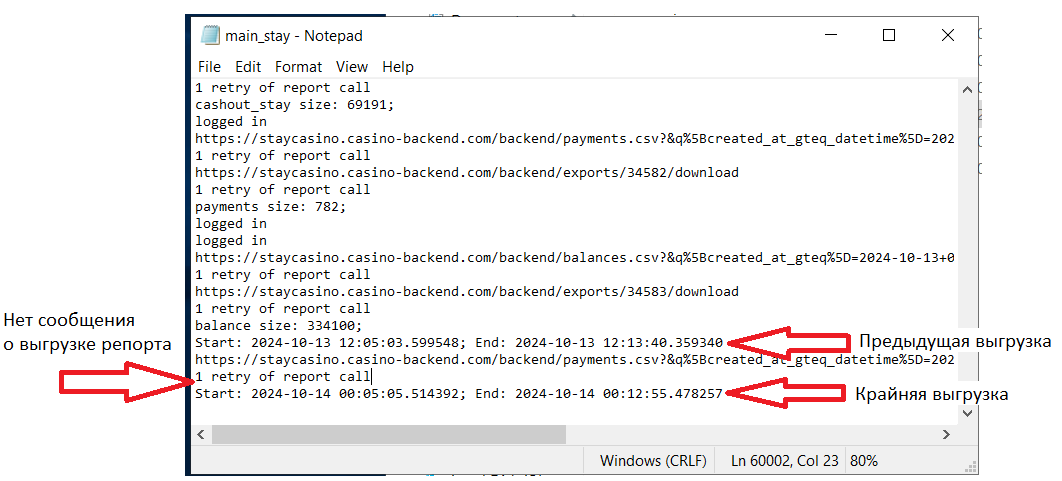
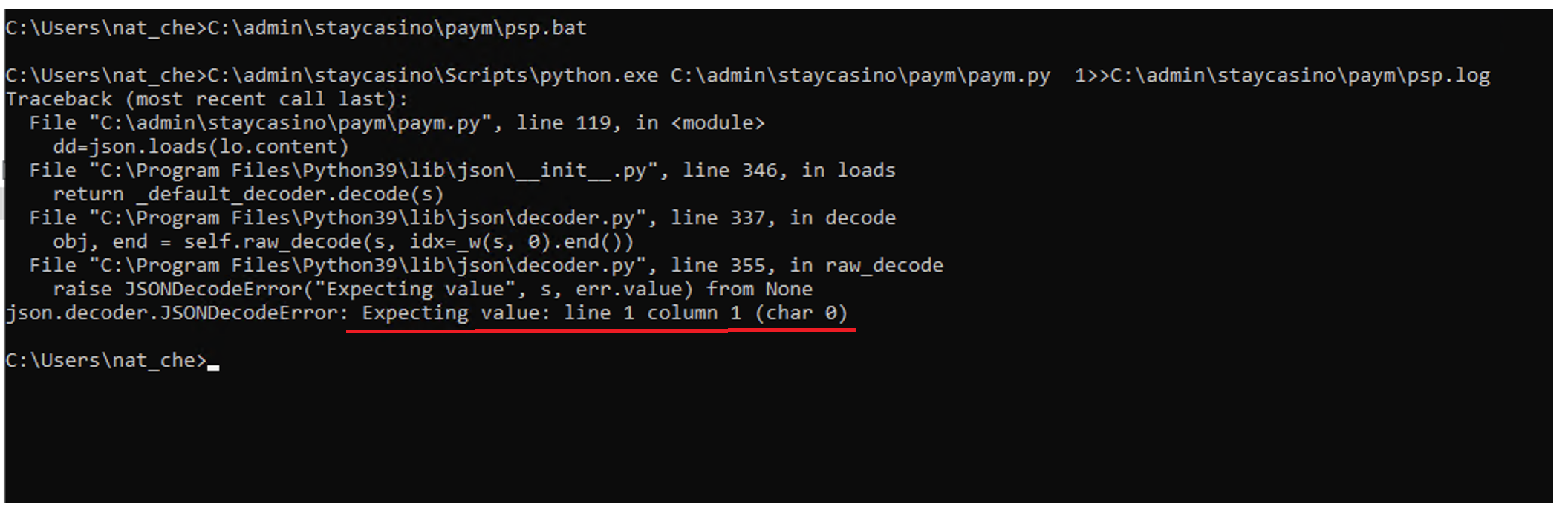
В первую очередь пробуем перезапустить выгрузку. Если видим похожую надпись - скрипт либо не может залогиниться, либо что-то со ссылкой на репорт. Сама по себе эта ошибка говорит: “То, что ты скачал, является пустым или непонятного типа и из этого нельзя сделать таблицу”. Это может быть как какая-то ошибка, так и просто пустое поле.
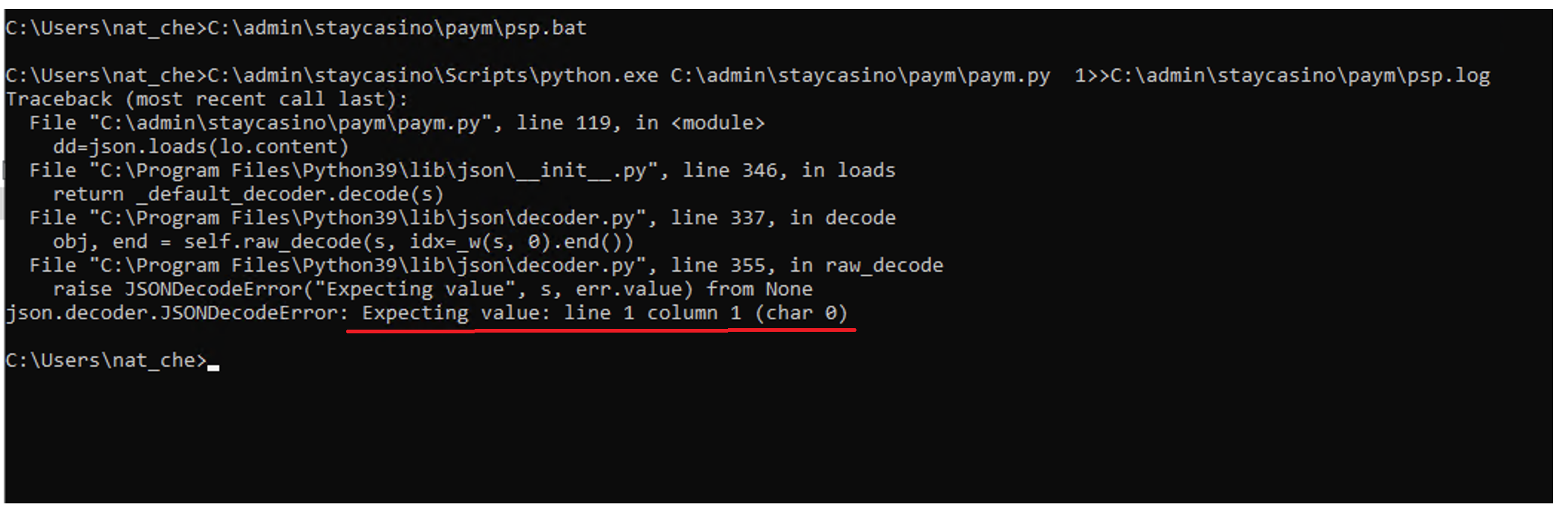
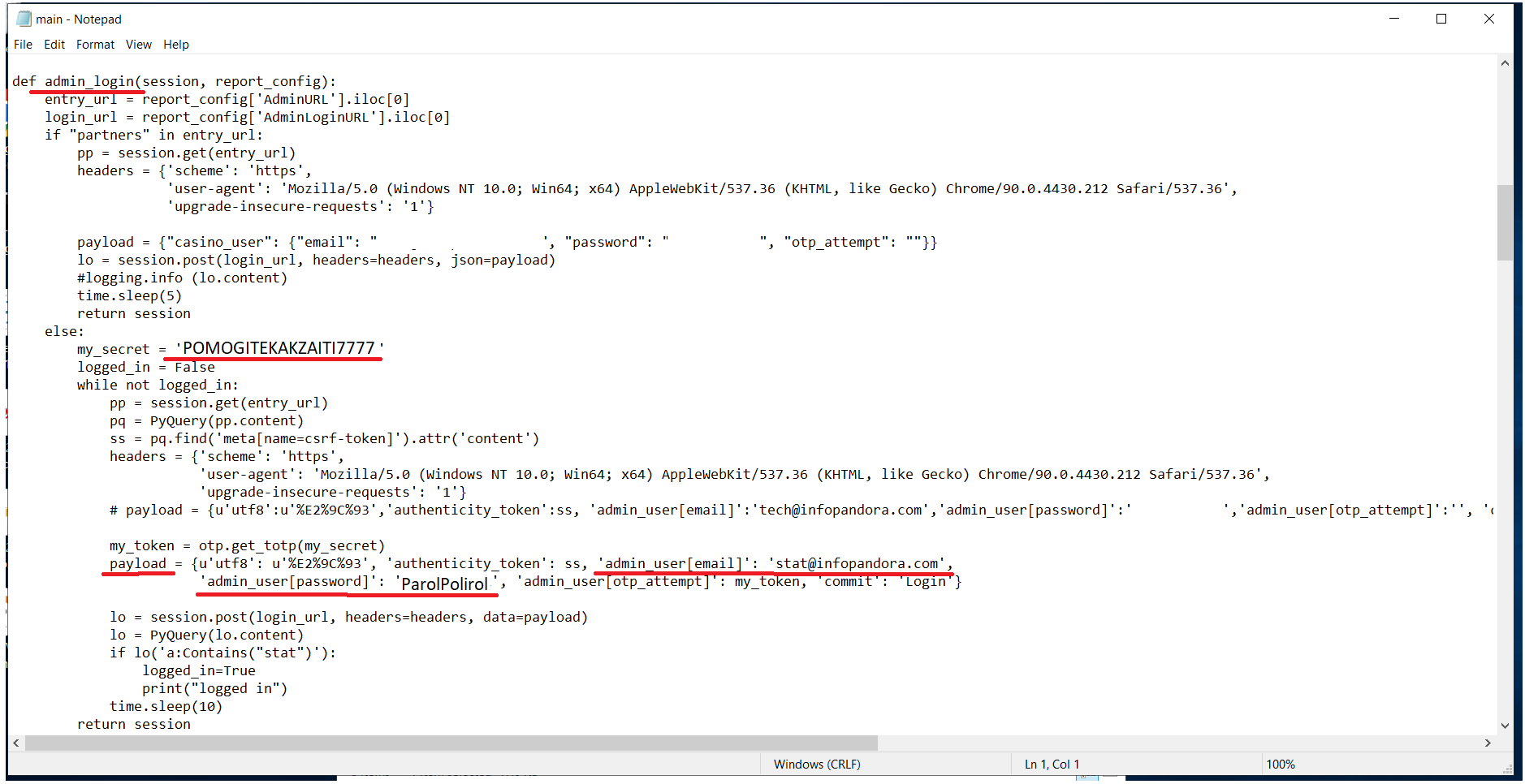
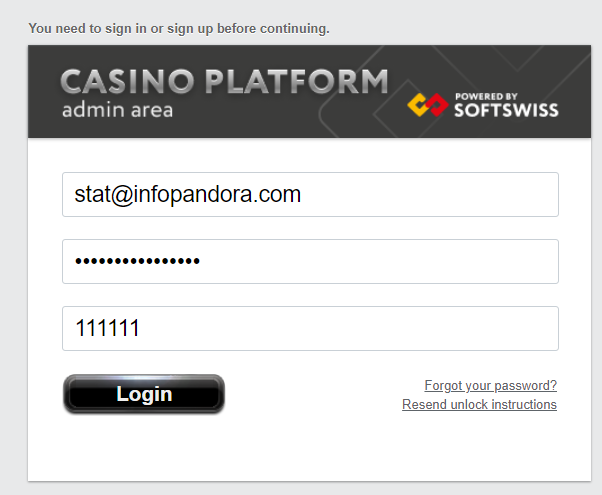
В таком случае проще всего попробовать вручную залогиниться и проверить репорт на выгрузку. В каждом скрипте есть креды для логина в админку, они находятся в функции admin_login. Большинство выгрузок происходят с акка stat@infopandora.com. Для входа в админку понадобится имейл, пароль, двухфакторный ключ.
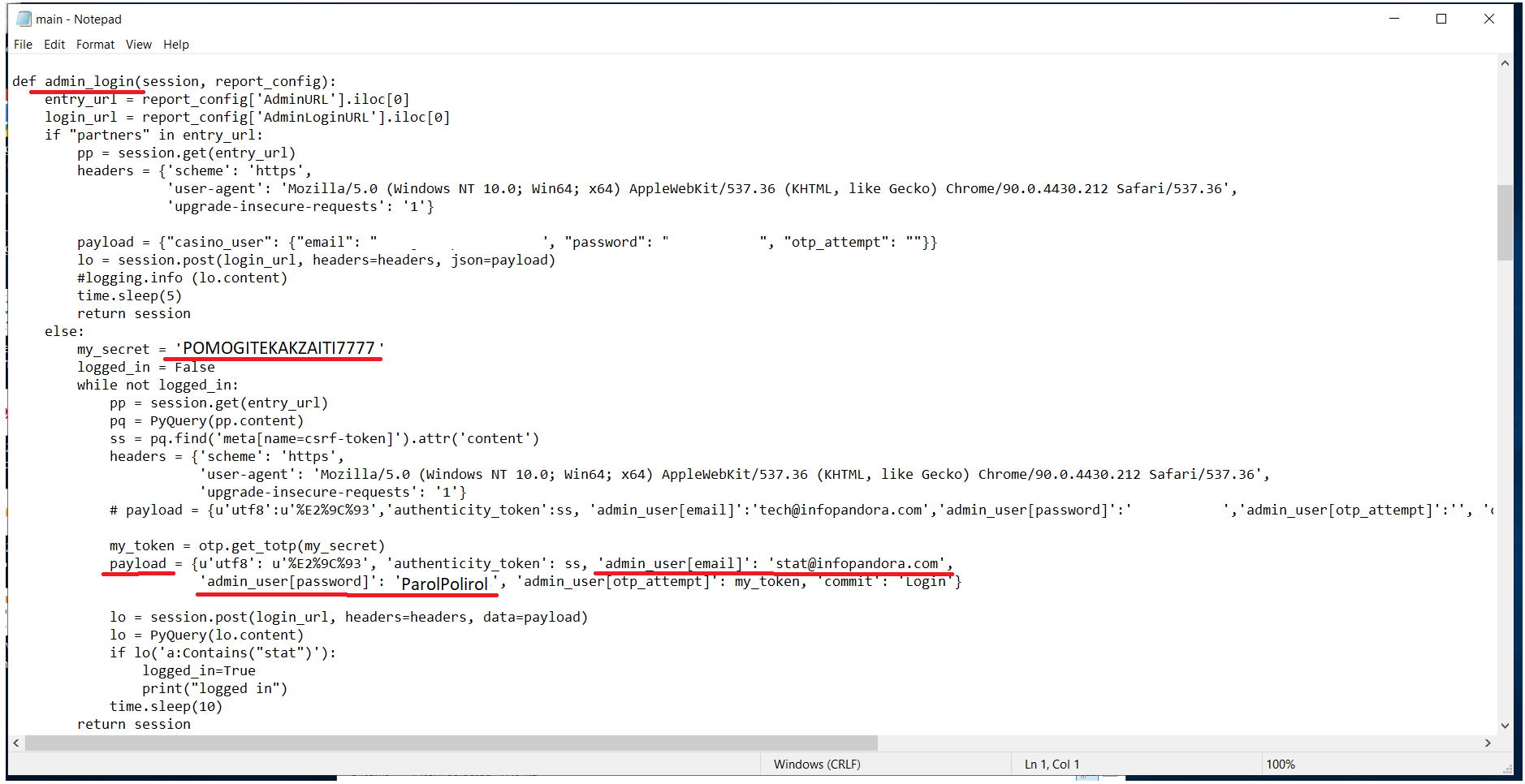
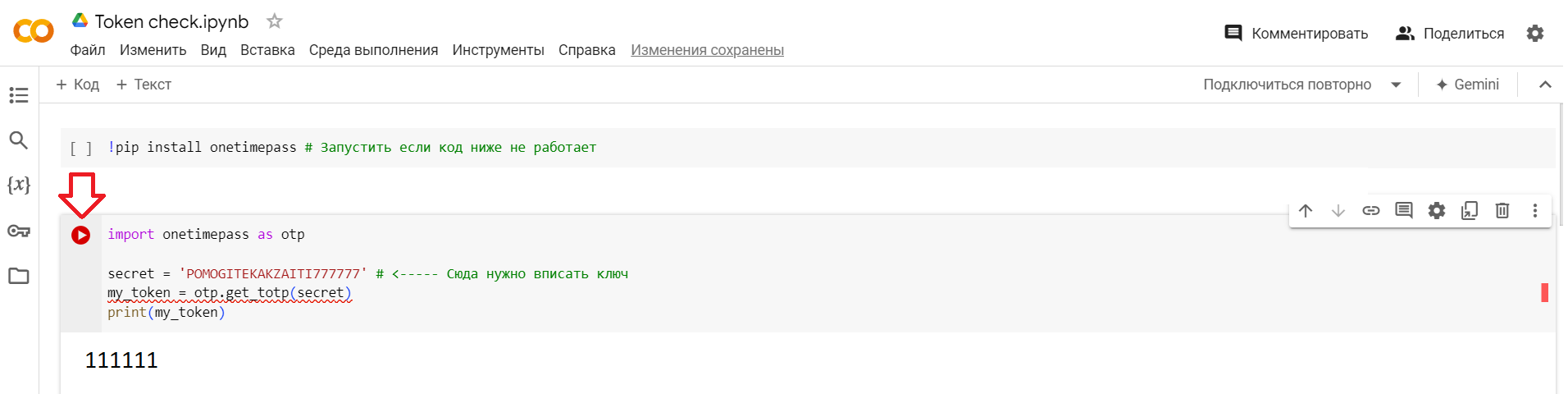
Двухфакторный ключ можно ввести себе в Гугл аутентификатор (или аналог) нажав на Добавить -> Ввести ключ настройки. В крайнем случае можно воспользоваться вот этой штукой, там нужно подставить нужный вам ключ и нажать запуск. ПОСЛЕ ИСПОЛЬЗОВАНИЯ КЛЮЧ (те большие буквы и цифры, которые вы вставляли) ОБЯЗАТЕЛЬНО СТЕРЕТЬ.
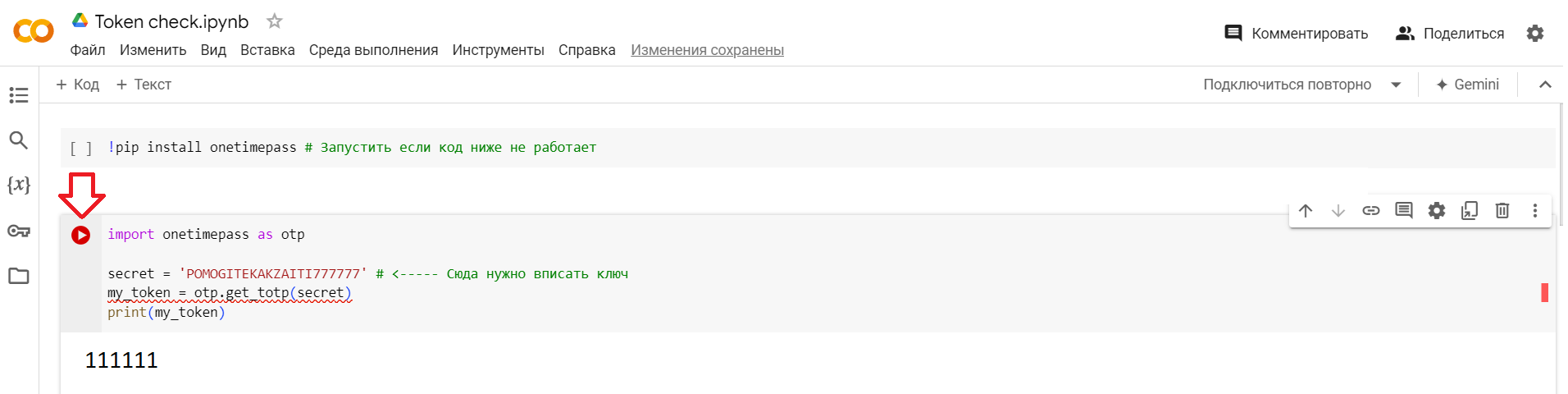
После этого пытаемся логиниться. ПОМНИМ ЧТО КЛЮЧ, который получали выше, ВРЕМЕННЫЙ и с первого раза может не сработать. Если попытались два раза зайти и не получилось - ВСЁ ПЕРЕПРОВЕРЯЕМ. Правильные ли пароли, ключи, админку используем? Если всё правильно, пытаемся еще раз и не заходит - скорее всего заблочился акк админки. В этом случае не стесняемся и пишем VadymK об этом (да, даже если этот талантливейший автор в отпуске, нормальный алгоритм будет чуть позднее). Это дело двух минут, просто доступ к почте есть только у меня.
Если зайти удалось, то проверяем ссылку. Просто копируем её полностью и вставляем в браузер.
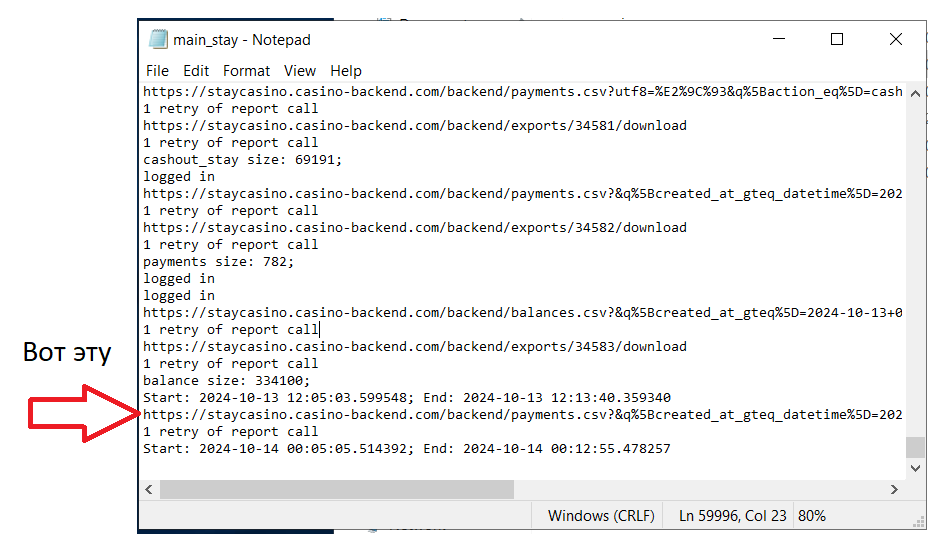
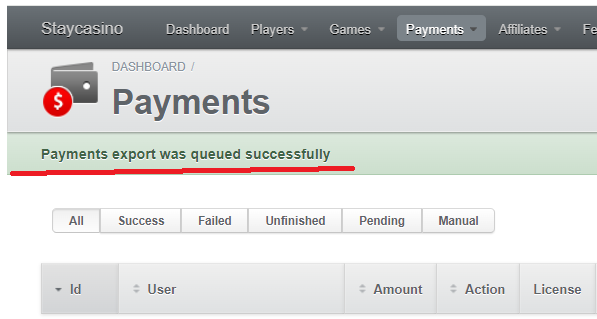
Должна либо начаться загрузка репорта, либо появиться вот такая надпись. Опять же, тут ситуативно от репорта к репорту. В некоторых у вас может просто открыться страница с данными в формате джейсон. Если ссылка не работает - СС что-то поменял в АПИ и её нужно пересмотреть. Вручную заходите в нужный репорт, выставляете фильтры и сравниваете с тем, что было.
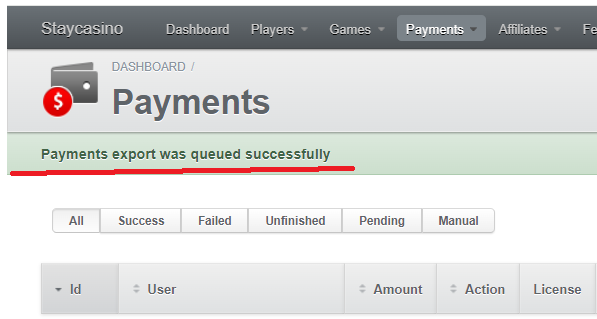
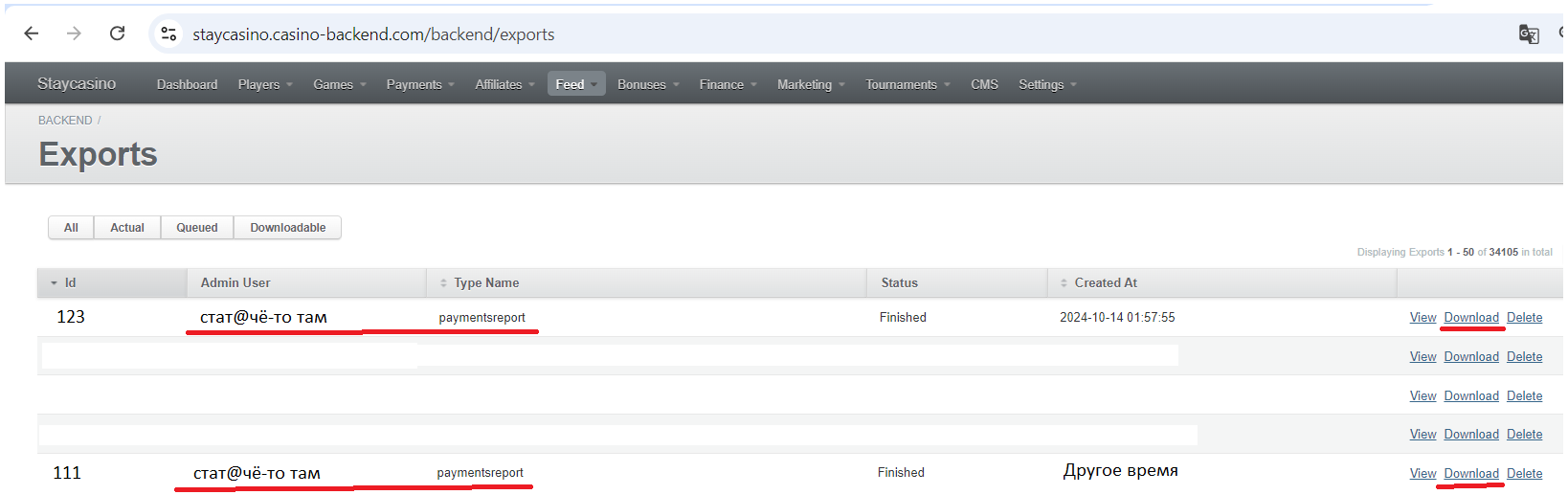
Если всё нормально, заходим в exports и проверяем (если репорт сам сразу не скачался). Если мы дошли до этого момента и всё было нормально, то скачиваем сформированный только что репорт и сравниваем его с тем, что был до этого. Тут уже могут быть разные варианты: мог поменяться тип файла (раньше скачивался .csv, а сейчас .zip), репорт мог разбиться на несколько частей (раньше всё было одним файлом, а теперь несколькими) и т.д. Если на этом этапе проблема не обнаружилась, то она уникальна и тут нужно уже пошагово запускать скрипт и на каждом этапе следить за тем, куда мы делаем запрос, что получаем, куда передаём и т.д.
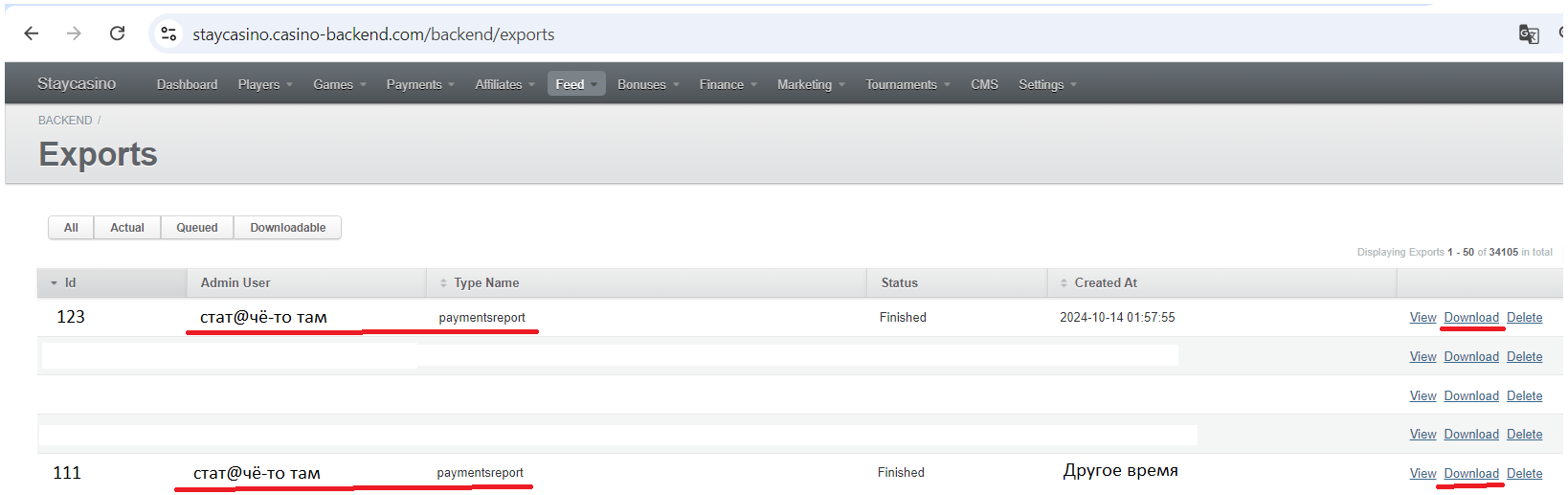
Вторая ситуация - проблемы с загрузкой репорта в Bigquery
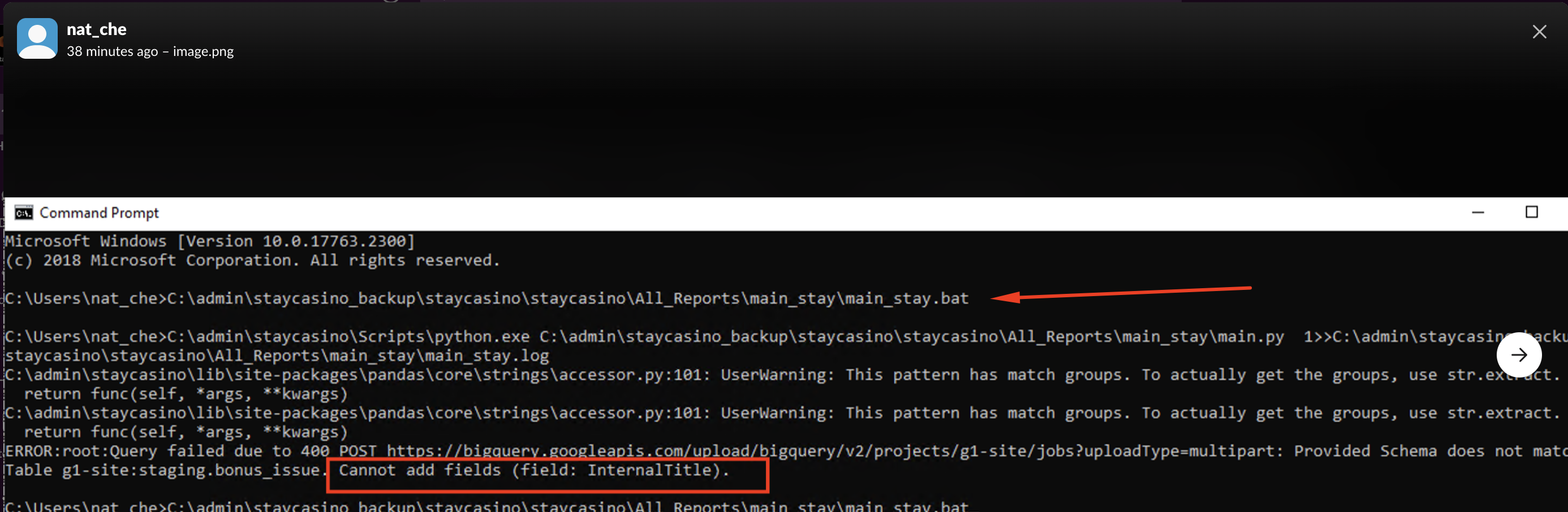
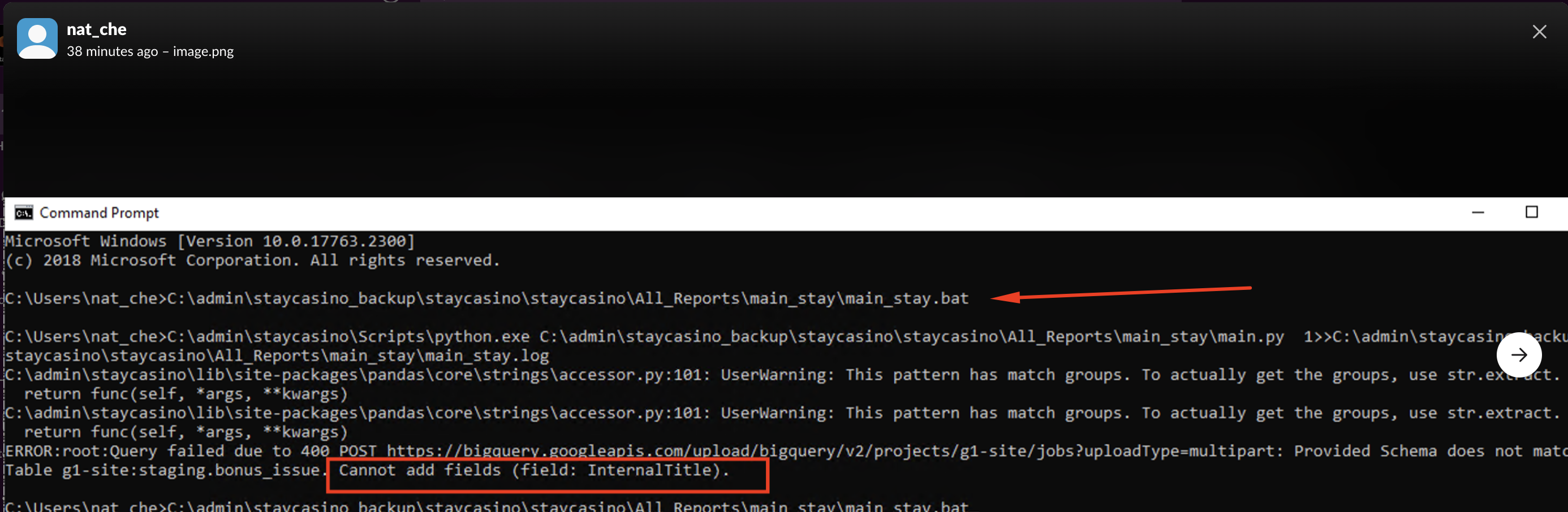
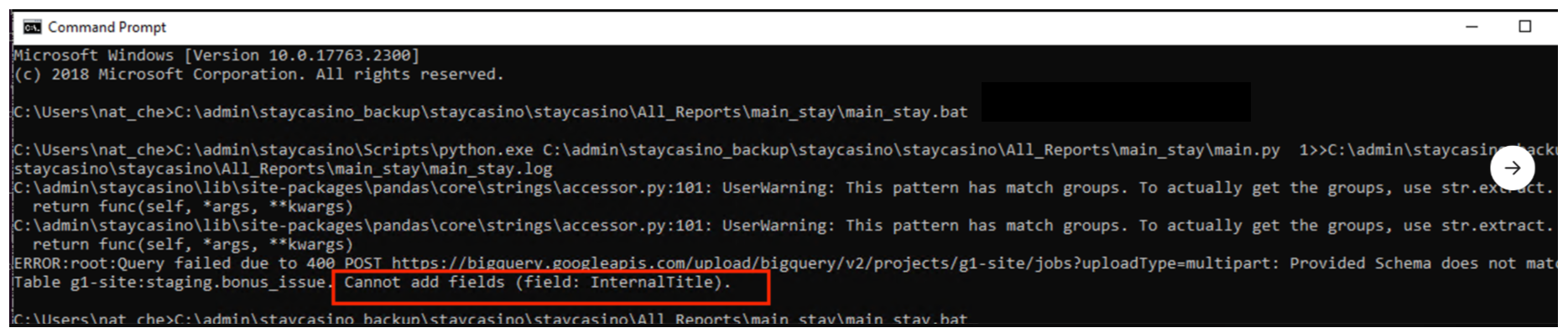
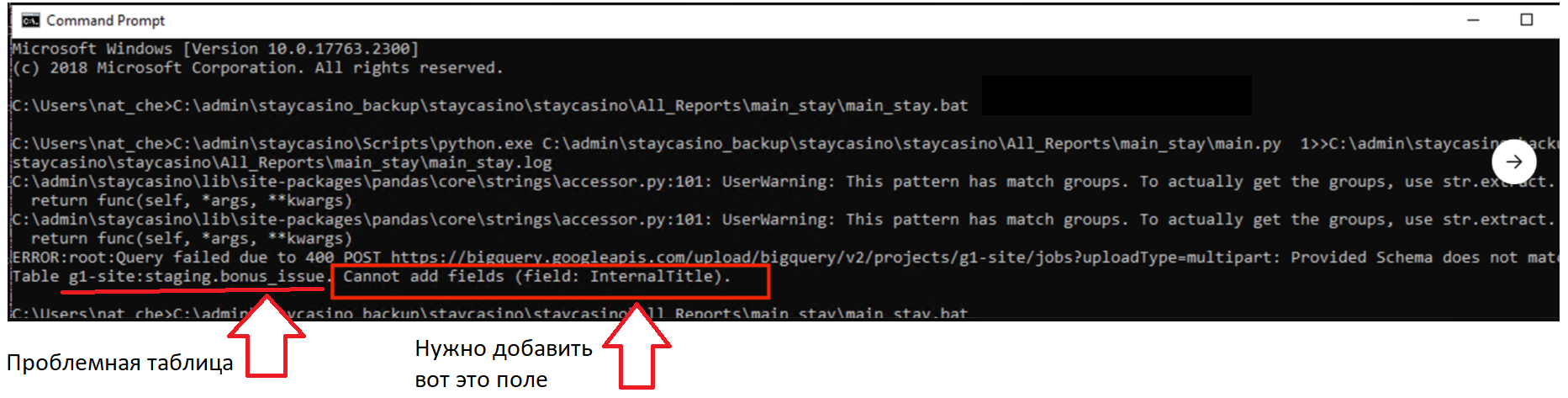
Если мы видим сообщение из экспортс, но не видим названия репорта с его размером, то тут дело в каких-то изменениях, из-за которых мы не смогли загрузить таблицу в BigQuerry, а с аккаунтом все нормально.
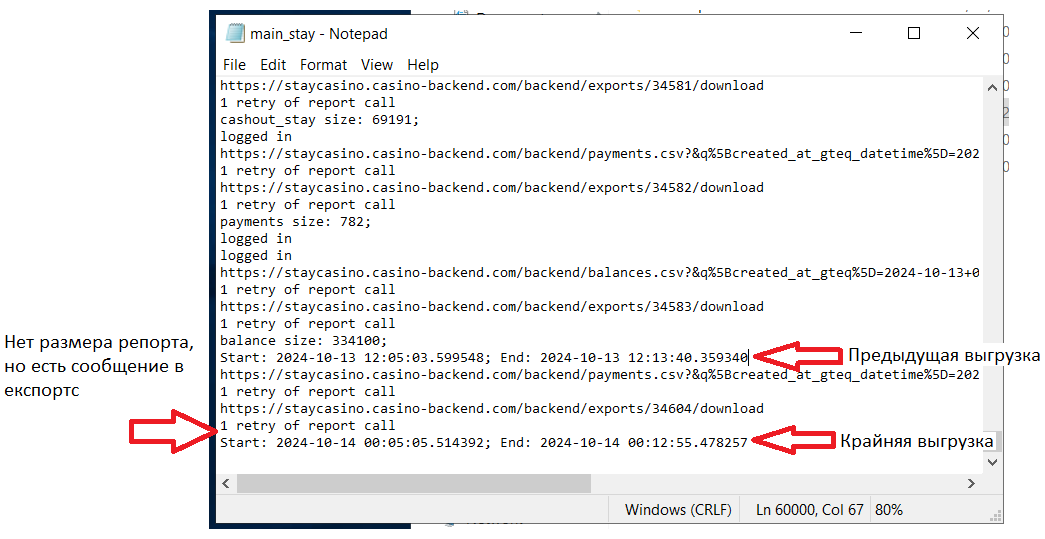
При перезапуске скрипта может возникнуть вот такая ошибка. Она означает, что в выгружаемой таблице появилось новое поле, которое мешает загрузить репорт в бигквери. В самой ошибке будет указана и таблица, и поле.
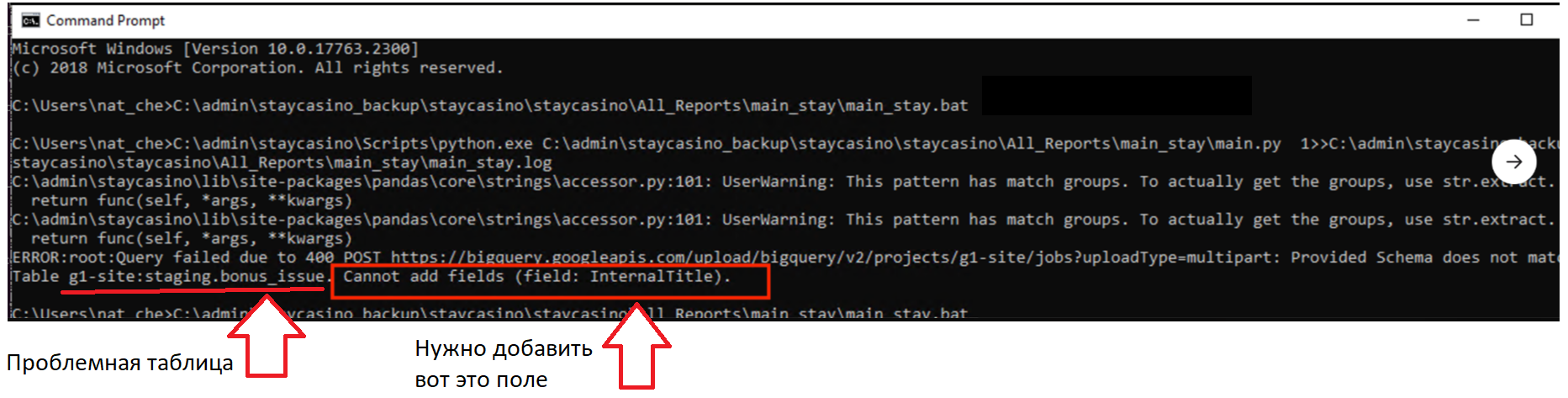
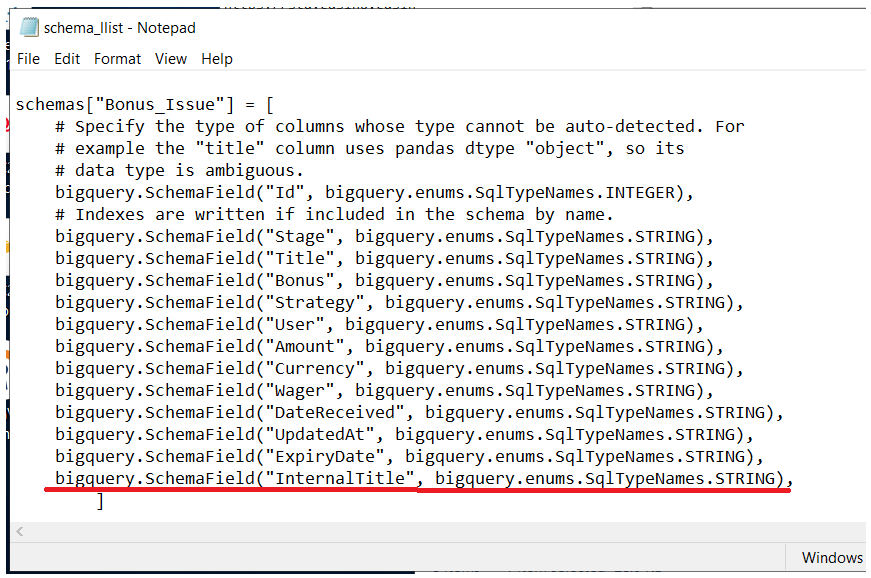
Зная нужное поле и таблицу первым делом идём добавлять его в файл schema_list, который находится в папке с репортом. Ищем нужную таблицу и добавляем туда колонку с этим названием (нужно выбрать подходящий тип данных либо STRING), сохраняем файл.
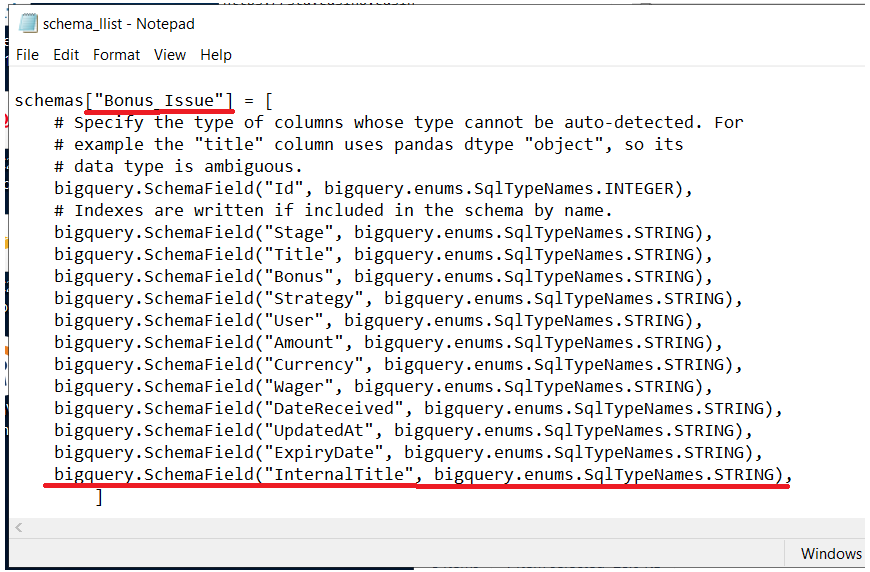
Дальше идём в бигквери и добавляем в саму таблицу эту колонку с тем же типом данных, что и в схеме.
ALTER TABLE `g1-site.staging.bonus_issue` ADD COLUMN InternalTitle string
Проблема должна быть решена, перезапускаем скрипт ещё раз. Если там появляется новая колонка - повторяем упражнение.
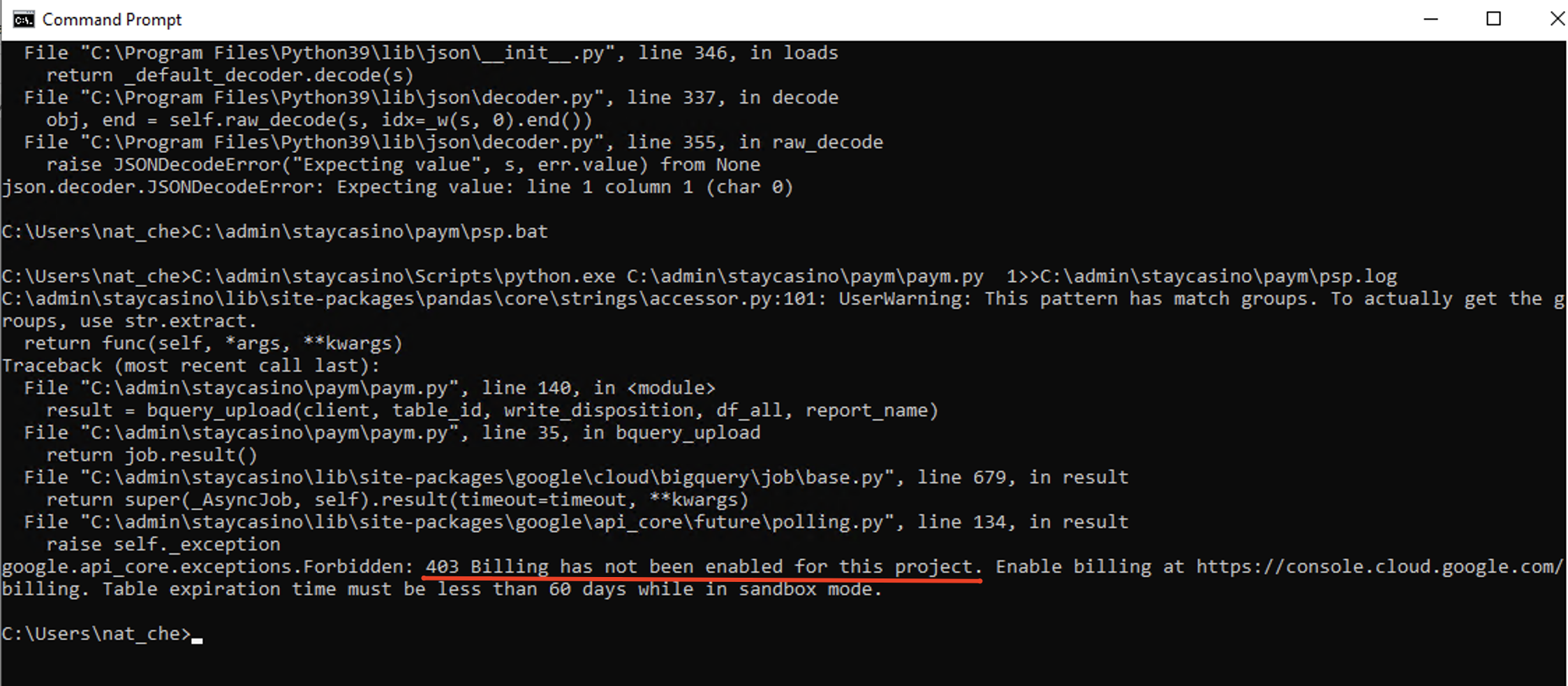
Исключительные ситуации происходят при получении ошибки из-за биллинга проекта. В таких случаях нужно сообщить об этом своему непосредственному руководителю.
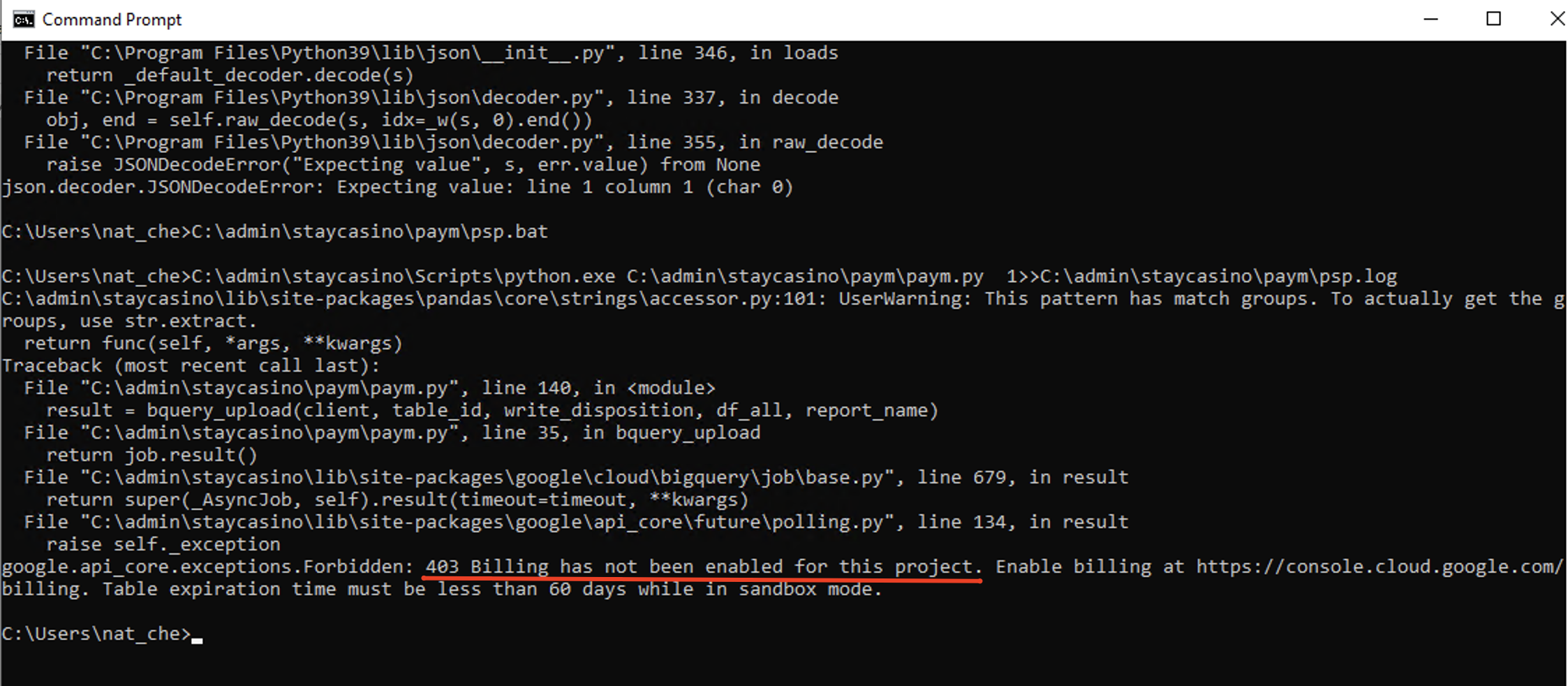
В иных случаях повторяем действия как в “Первой ситуации“.
Третья ситуация - Выгрузка даже не запустилась
В таких случаях в логах будет просто отсутствовать запись о выгрузке в дату, за которую она должна быть. Это говорит о том, что она даже не запускалась.
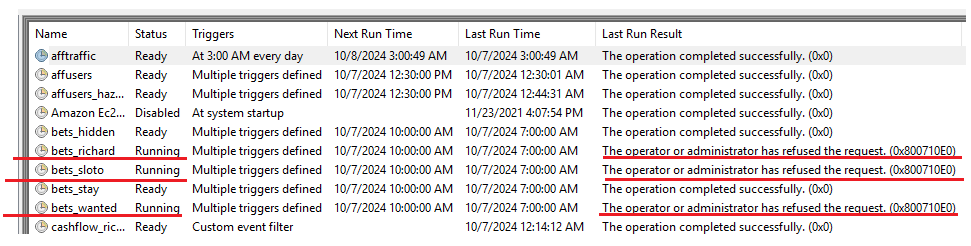
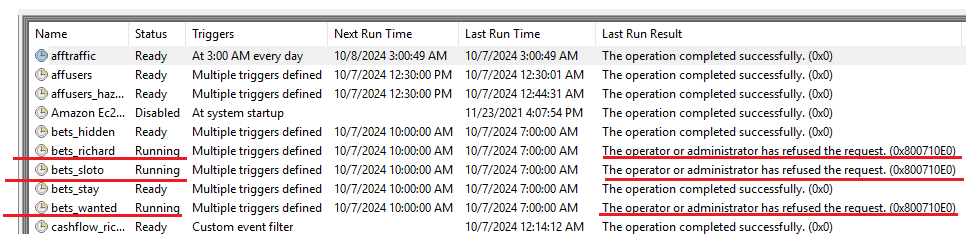
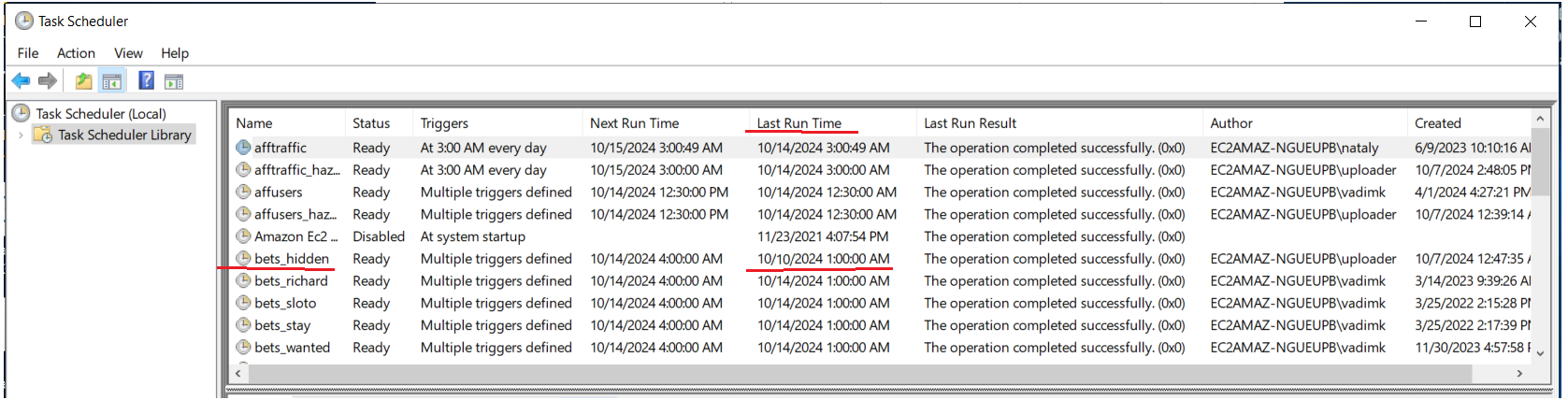
Тут может возникнуть ситуация, при которой предыдущая выгрузка не завершилась и “зависла“ в Task scheduler. Об этом будет говорить постоянно висящий статус “Running“, а в последнем результате - отказ от выполнения. В таких случаях нужно нажать на скрипт правой кнопкой и остановить его. Именно остановить, а не отключить. После этого статус должен поменяться на “Ready“ и скрипт можно запустить либо прямо тут, либо из папки.
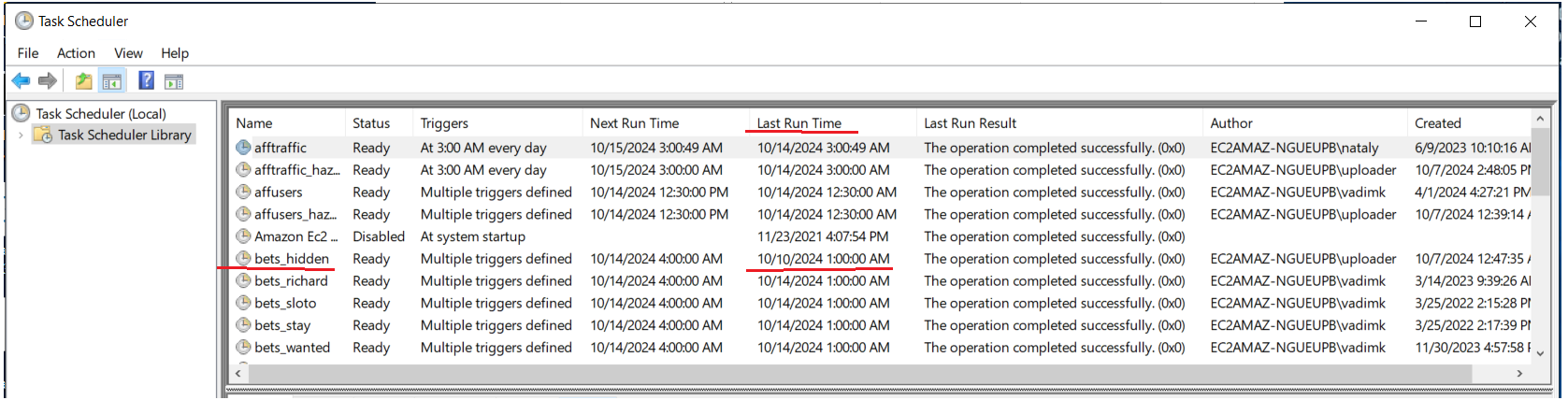
Другая ситуация состоит в том, что таска просто не запускается в нужное время. У неё будет выделяться только Last time run, так как она не запускалась в прошлые разы, когда нужно было. При этом все остальные параметры будут в норме. Пока не понятно, почему так происходит с некоторыми скриптами и лучшее решение - удалить эту такску и создать новую с теми же параметрами.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}