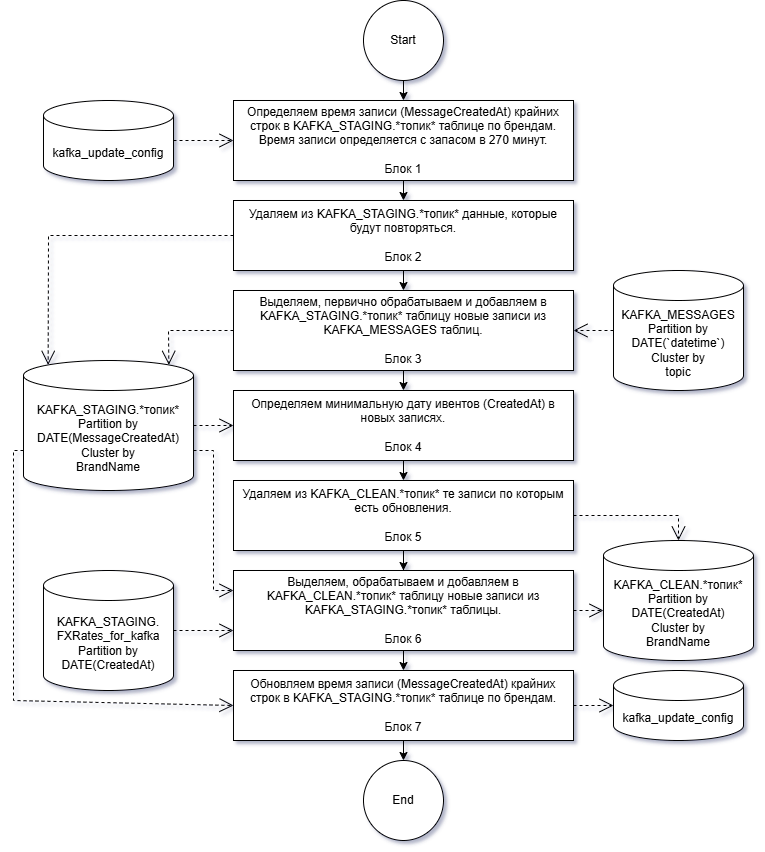
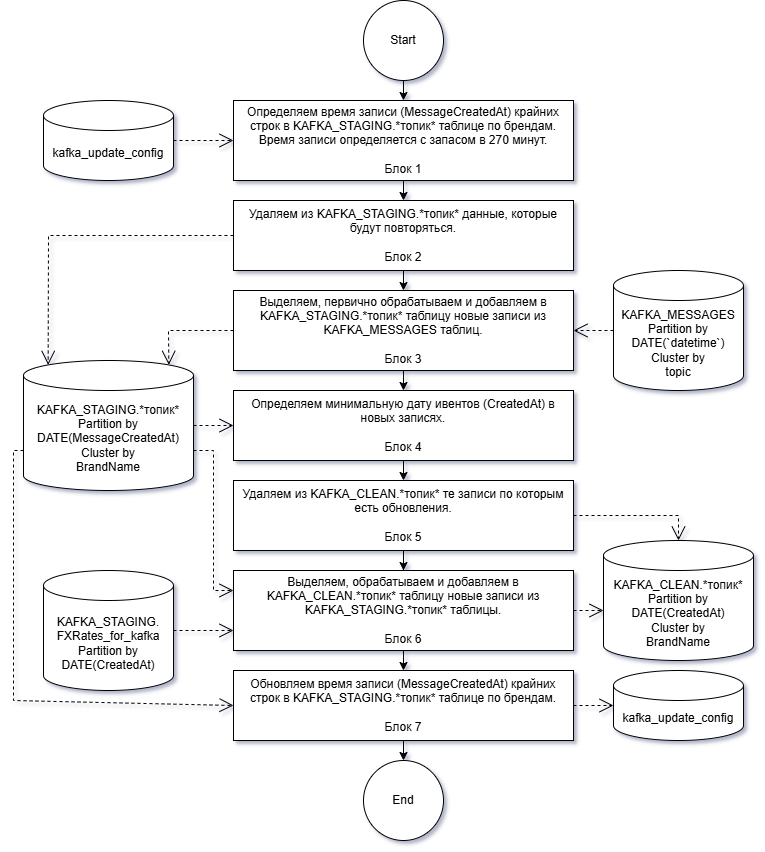
Обновление KAFKA таблицы является многоэтапным и задействует несколько таблиц. Если свести алгоритм к очень простому виду, то мы должны:
Определить насколько старые записи мы будем обновлять;
В стейджинг таблице удалить те данные, которые мы сейчас перепишем;
Первично обработать и добавить в стейджинг таблицу данные из источника с сырыми данными;
В клин таблице удалить те данные, которые мы сейчас обновим;
Обработать и добавить в клин таблицу данные из стейджинг таблицы;
Зафиксировать время обновления.
Запросы:
update_kafka_balance_transaction
update_kafka_bonus_issue
update_kafka_payments
update_kafka_freespin_issue
update_kafka_user_info (Запрос отличается от представленного алгоритма, но смысл тот же)
Блок 1
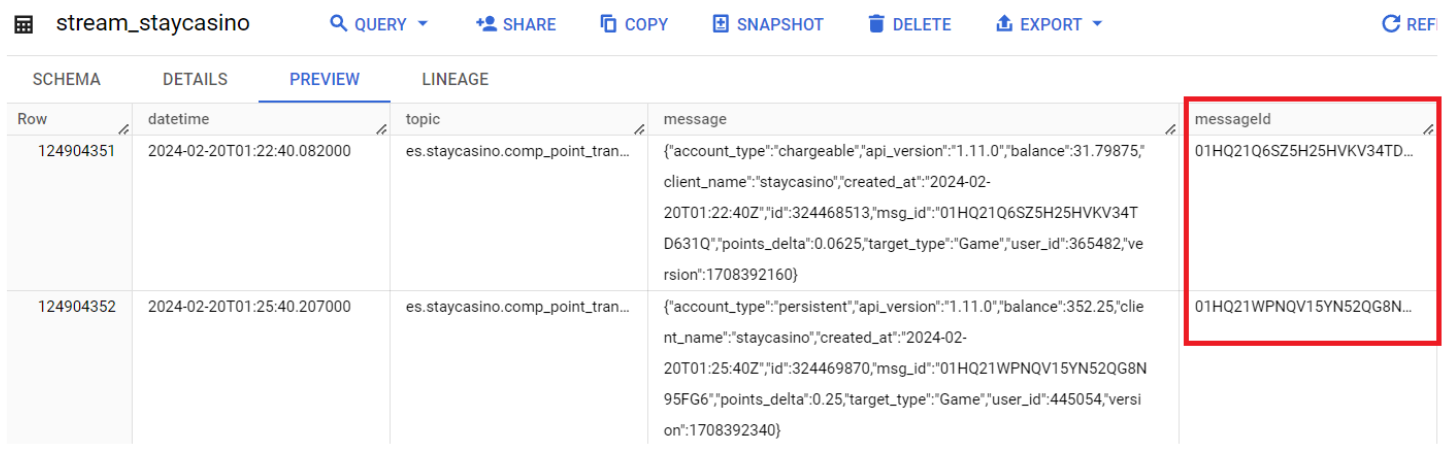
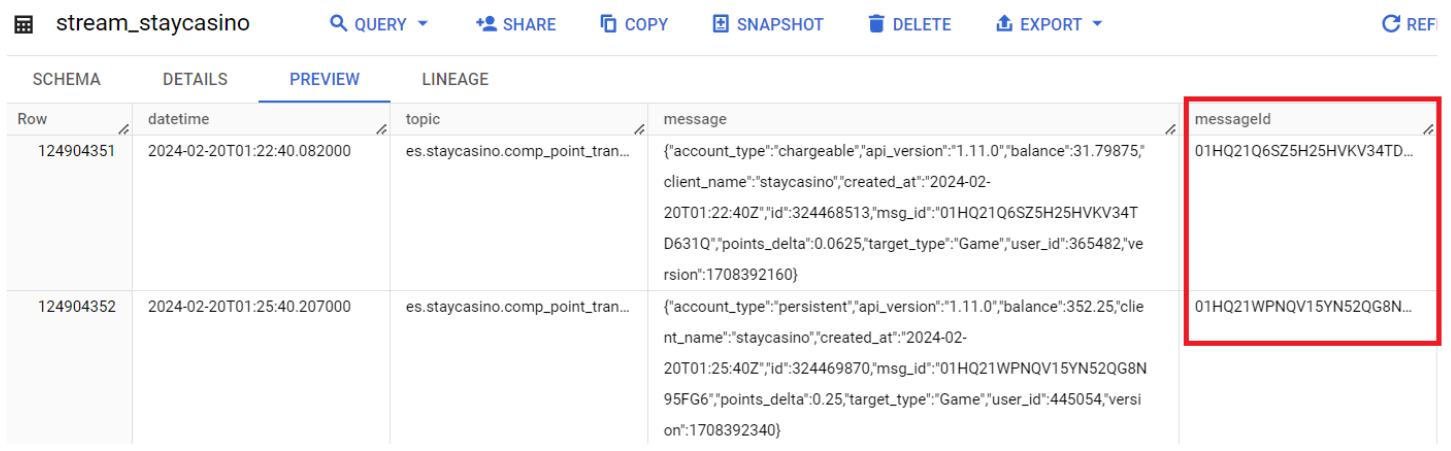
Первоначально нам нужно понять какие поля новые, а какие старые. Для этого идеально подходит столбец “messageId”, который показан на скриншоте 2.1. Но мы не можем его использовать, как как эти айди имеют свойство переставать записываться в таблицу, как на скриншоте 2.2. Поэтому во всех наших обновлениях мы будем использовать только колонки времени “datetime”.
В конце скрипта мы будем записывать в таблицу `g1-site.KAFKA_STAGING.kafka_update_config` время получения последних записей в разбивке по брендам. В данном блоке мы записываем эти данные в массив [stay, sloto, richard, wanted]. Далее в коде мы будем обращаться к нужному времени по индексам: Стей - 0; Слото - 1; Ричард - 2; Вонтед - 3 и т.д.
Разбивка нам нужна из-за нестабильности заполнения таблиц “KAFKA_MESSAGES”. Например, в колонке “topic” платежные данные сейчас обозначаются как “es.staycasino.payment” или “payment”, но в будущем в какой-то из таблиц это обозначение может измениться, из-за чего будут отсутствовать данные по бренду. С текущими установками нужно будет просто указать новое обозначение и данные дозагрузятся, дополнительные действия будут не нужны.
Также в таблицах могут появляться разные задержки в записях (скрин 2.3), например, раньше между Стеем и Слото разница в час. С текущей системой такая разность не потребует дополнительных действий при появлении данных.
Время крайнего обновления мы будем брать с запасом в 270 минут. Например, если в таблице самая поздняя запись по столбцу “datetime” это “2023-02-21 05:00:00”, то мы будем обновлять все записи после “2023-02-21 00:30:00”, так как в таблицах есть задержки и часто запись с временем “2023-02-21 02:30:00” может появиться позднее чем запись с “2023-02-21 03:00:00”.
Блок 2
Из-за использования запаса в 90 минут нам всегда нужно удалять данные, которые мы будем перезаписывать, чтобы не создавать дубли в таблице. В этой части кода мы начинаем пользоваться свойствами таблиц с разделами. Таблица `g1-site.KAFKA_STAGING.*топик*` разбита на разделы по столбцу date(MessageCreatedAt). Благодаря фильтру date(MessageCreatedAt) >= date(total_last_datetime) мы задействуем только те разделы, которые нам нужны, это позволяет экономить ресурсы. Пример эффективности использования таблицы с разделами показан на скрине 2.4.
Блок 3
В данной части кода мы проводим первичную обработку и добавление данных в таблицу `g1-site.KAFKA_STAGING.*топик*` из таблиц с сырыми данными `g1-site.KAFKA_MESSAGES.kafkastream_бренд`.
Блок 4
Определяем самую раннюю дату платежного ивента. С помощью неё мы будем фильтровать разделы таблиц при удалении устаревших записей и конвертации валют.
Блок 5
Удаление устаревших записей для их последующего обновления в таблице `g1-site.KAFKA_CLEAN.*топик*`.
Блок 6
В этом блоке в первую очередь мы выделяем нужные для обновления данные из таблицы `g1-site.KAFKA_STAGING.*топик*`. Благодаря сегментированию по столбцу “BrandName” и разбивке на разделы по date(MessageCreatedAt) данная операция затрагивает минимум неиспользуемых ресурсов. Для конвертации местной валюты используется таблица `g1-site.KAFKA_STAGING.FXRates_for_kafka`. В итоге в таблицу `g1-site.KAFKA_CLEAN.*топик*` записываются обработанные данные.
Блок 7
В таблицу `g1-site.KAFKA_STAGING.kafka_update_config` записываем время получения последних записей. Эта информация будет использоваться при следующем запуске скрипта.
{kind=link}
{kind=link}